查询引擎
TDengine TSDB 作为一个高性能的时序大数据平台,其查询与计算功能是核心组件之一。该平台提供了丰富的查询处理功能,不仅包括常规的聚合查询,还涵盖了时序数据的窗口查询、统计聚合等高级功能。这些查询计算任务需要 taosc、vnode、qnode 和 mnode 之间的紧密协作。在一个复杂的超级表聚合查询场景中,可能需要多个 vnode 和 qnode 共同承担查询和计算的职责。关于 vnode、qnode、mnode 的定义和介绍,请参考 系统架构
各模块在查询计算中的职责
taosc
taosc 负责解析和执行 SQL。对于 insert 类型的 SQL,taosc 采用流式读取解析策略,以提高处理效率。而对于其他类型的 SQL,taosc 首先使用语法解析器将其分解为抽象语法树(Abstract Syntax Tree,AST),在解析过程中对 SQL 进行初步的语法校验。如果发现语法错误,taosc 会直接返回错误信息,并附上错误的具体位置,以帮助用户快速定位和修复问题。
解析完成的 AST 被进一步转换为逻辑查询计划,逻辑查询计划经过优化后进一步转换为物理查询计划。接着,taosc 的调度器将物理查询计划转换为查询执行的任务,并将任务发送到选定的 vnode 或 qnode 执行。在得到查询结果准备好的通知后,taosc 将查询结果从相应的 vnode 或 qnode 取回,最终返回给用户。
taosc 的执行过程可以简要总结为:解析 SQL 为 AST,生成逻辑查询计划并优化后转为物理查询计划,调度查询任务到 vnode 或 qnode 执行,获取查询结果。
mnode
在 TDengine TSDB 集群中,超级表的信息和元数据库的基础信息都得到妥善管理。mnode 作为元数据服务器,负责响应 taosc 的元数据查询请求。当 taosc 需要获取 vgroup 等元数据信息时,它会向 mnode 发送请求。mnode 在收到请求后,会迅速返回所需的信息,确保 taosc 能够顺利执行其操作。
此外,mnode 还负责接收 taosc 发送的心跳信息。这些心跳信息有助于维持 taosc 与 mnode 之间的连接状态,确保两者之间的通信畅通无阻。
vnode
在 TDengine TSDB 集群中,vnode 作为虚拟节点,扮演着关键的角色。它通过任务队列的方式接收来自物理节点分发的查询请求,并执行相应的查询处理过程。每个 vnode 都拥 有独立的任务队列,用于管理和调度查询请求。
当 vnode 收到查询请求时,它会从任务队列中取出请求,并进行处理。处理完成后,vnode 会将查询结果返回给下级物理节点中处于阻塞状态的查询队列工作线程,或者是直接返回给 taosc。
执行器
执行器模块负责实现各种查询算子,这些算子通过调用 TSDB 的数据读取 API 来读取数据内容。数据内容以数据块的形式返回给执行器模块。TSDB 是一个时序数据库,负责从内存或硬盘中读取所需的信息,包括数据块、数据块元数据、数据块统计数据等多种类型的信息。
TSDB 屏蔽了下层存储层(硬盘和内存缓冲区)的实现细节和机制,使得执行器模块可以专注于面向列模式的数据块进行查询处理。这种设计使得执行器模块能够高效地处理各种查询请求,同时简化数据访问和管理的复杂性。
UDF Daemon
在分布式数据库系统中,执行 UDF 的计算节点负责处理涉及 UDF 的查询请求。当查询中使用了 UDF 时,查询模块会负责调度 UDF Daemon 完成对 UDF 的计算,并获取 计算结果。
UDF Daemon 是一个独立的计算组件,负责执行用户自定义的函数。它可以处理各种类型的数据,包括时序数据、表格数据等。通过将 UDF 的计算任务分发给 UDF Daemon,查询模块能够将计算负载从主查询处理流程中分离出来,提高系统的整体性能和可扩展性。
在执行 UDF 的过程中,查询模块会与 UDF Daemon 紧密协作,确保计算任务的正确执行和结果的及时返回。
查询策略
为了更好地满足用户的需求,TDengine TSDB 集群提供了查询策略配置项 queryPolicy,以便用户根据自己的需求选择查询执行框架。这个配置项位于 taosc 的配置文件,每个配置项仅对单个 taosc 有效,可以在一个集群的不同 taosc 中混合使用不同的策略。
queryPolicy 的值及其含义如下。
- 1:表示所有查询只使用 vnode(默认值)。
- 2:表示混合使用 vnode/qnode(混合模式)。
- 3:表示查询中除了扫表功能使用 vnode 以外,其他查询计算功能只使用 qnode。
- 4:表示使用客户端聚合模式。
通过选择合适的查询策略,用户可以灵活地分配控制查询资源在不同节点的占用情况,从而实现存算分离、追求极致性能等目的。
SQL 说明
TDengine TSDB 通过采用 SQL 作为查询语言,显著降低了用户的学习成本。在遵循标准 SQL 的基础上,结合时序数据库的特点进行了一系列扩展,以更好地支持时序数据库的特色查询需求。
- 分组功能扩展:TDengine TSDB 对标准 SQL 的分组功能进行了扩展,引入了 partition by 子句。用户可以根据自定义维度对输入数据进行切分,并在每个分组内进行任意 形式的查询运算,如常量、聚合、标量、表达式等。
- 限制功能扩展:针对分组查询中存在输出个数限制的需求,TDengine TSDB 引入了 slimit 和 soffset 子句,用于限制分组个数。当 limit 与 partition by 子句共用时,其含义转换为分组内的输出限制,而非全局限制。
- 标签查询支持:TDengine TSDB 扩展支持了标签查询。标签作为子表属性,可以在查询中作为子表的伪列使用。针对仅查询标签列而不关注时序数据的场景,TDengine TSDB 引入了标签关键字加速查询,避免了对时序数据的扫描。
- 窗口查询支持:TDengine TSDB 支持多种窗口查询,包括时间窗口、状态窗口、会话窗口、事件窗口、计数窗口等。未来还将支持用户自定义的更灵活的窗口查询。
- 关联查询扩展:除了传统的 Inner、Outer、Semi、Anti-Semi Join 以外,TDengine TSDB 还支持时序数据库中特有的 ASOF Join 和 Window Join。这些扩展使得用户可以更加方便灵活地进行所需的关联查询。
查询流程
完整的查询流程如下。
- 第 1 步,taosc 解析 SQL 并生成 AST。元数据管理模块(Catalog)根据需要向 vnode 或 mnode 请求查询中指定表的元数据信息。然后,根据元数据信息对其进行权限检查、语法校验和合法性校验。
- 第 2 步,完成合法性校验之后生成逻辑查询计划。依次应用全部的优化策略,扫描执行计划,进行执行计划的改写和优化。根据元数据信息中的 vgroup 数量和 qnode 数量信息,基于逻辑查询计划生成相应的物理查询计划。
- 第 3 步,客户端内的查询调度器开始进行任务调度处理。一个查询子任务会根据其数据亲缘关系或负载信息调度到某个 vnode 或 qnode 所属的 dnode 进行处理。
- 第 4 步,dnode 接收到查询任务后,识别出该查询请求指向的 vnode 或 qnode,将消息转发到 vnode 或 qnode 的查询执行队列。
- 第 5 步,vnode 或 qnode 的查询执行线程从查询队列获得任务信息,建立基础的查询执行环境,并立即执行该查询。在得到部分可获取的查询结果后,通知客户端调度器。
- 第 6 步,客户端调度器依照执行计划依次完成所有任务的调度。在用户 API 的驱动下,向最上游算子所在的查询执行节点发送数据获取请求,读取数据请求结果。
- 第 7 步,算子依据其父子关系依次从下游算子获取数据并返回。
- 第 8 步,taosc 将所有获取的查询结果返回给上层应用程序。
多表聚合查询流程
TDengine TSDB 为了解决实际应用中对不同数据采集点数据进行高效聚合的问题,引入了超级表的概念。超级表是一种特殊的表结构,用于代表一类具有相同数据模式的数据采集点。超级表实际上是一个包含多张表的表集合,每张表都具有相同的字段定义,但每张表都带有独特的静态标签。这些标签可以有多个,并且可以随时增加、删除和修改。
通过超级表,应用程序可以通过指定标签的过滤条件,轻松地对一个超级表下的全部或部分表进行聚合或统计操作。这种设计大大简化了应用程序的开发过程,提高了数据处理的效率和灵活性。TDengine TSDB 的多表聚合查询流程如下图所示:
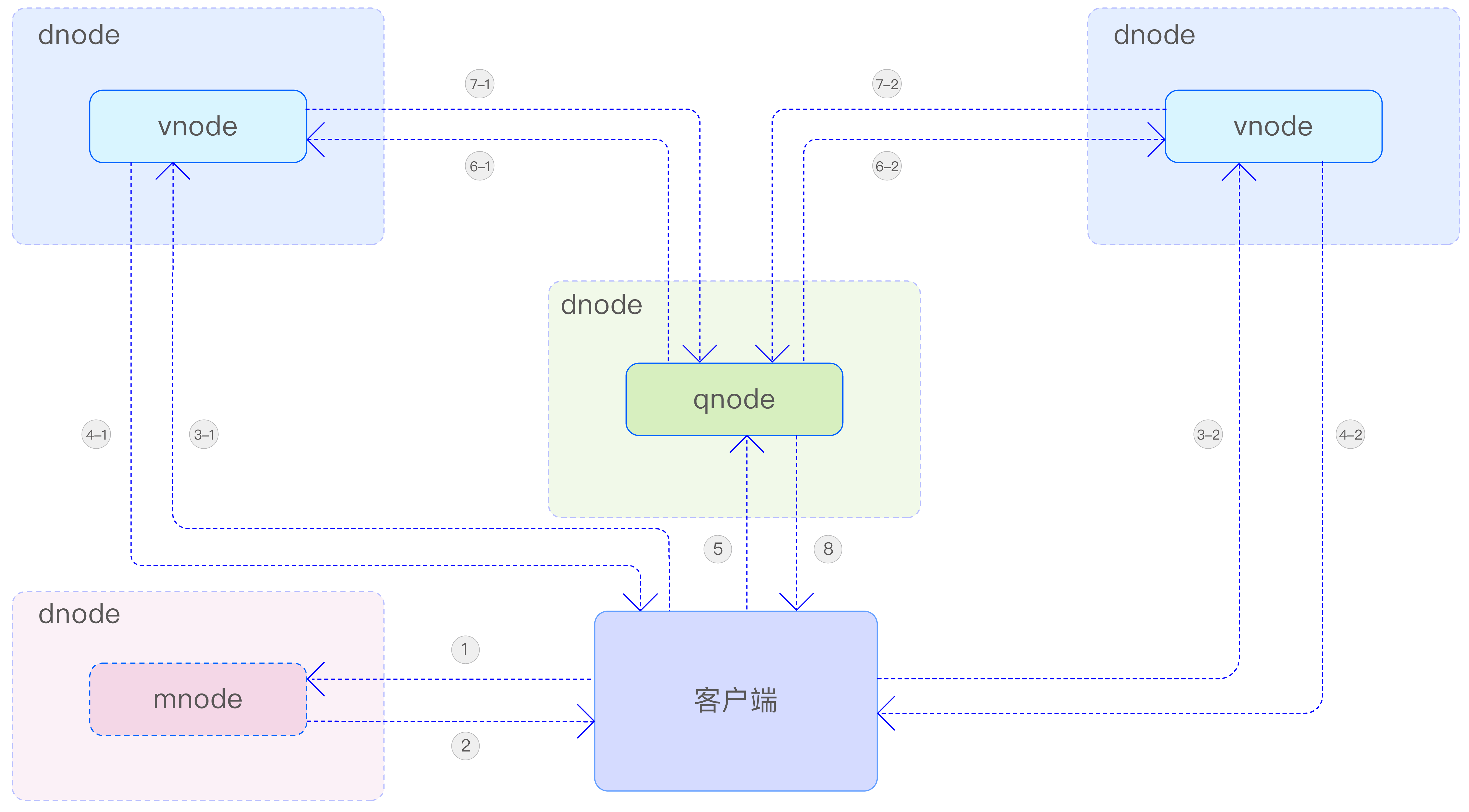
具体步骤说明如下。
- 第 1 步,taosc 从 mnode 获取库和表的元数据信息。
- 第 2 步,mnode 返回请求的元数据信息。
- 第 3 步,taosc 向超级表所属的每个 vnode 发送查询请求。
- 第 4 步,vnode 启动本地查询,在获得查询结果后返回查询响应。
- 第 5 步,taosc 向聚合节点(在本例中为 qnode)发送查询请求。
- 第 6 步,qnode 向每个 vnode 节点发送数据请求消息来拉取数据。
- 第 7 步,vnode 返回本节点的查询计算结果。
- 第 8 步,qnode 完成多节点数据聚合后将最终查询结果返回给客户端。
TDengine TSDB 为了提升聚合计算速度,在 vnode 内实现了标签数据与时序数据的分离存储。首先,系统会在内存中过滤标签数据,以确定需要参与聚合操作的表的集合。这样做可以显著减少需要扫描的数据集,从而大幅提高聚合计算的速度。
此外,得益于数据分布在多个 vnode 中,聚合计算操作可以在多个 vnode 中并发进行。这种分布式处理方式进一步提高了聚合的速度,使得 TDengine TSDB 能够更高效地处理大规模时序数据。
值得注意的是,对普通表的聚合查询以及绝大部分操作同样适用于超级表,且语法完全一致。具体请查询参考手册。
查询缓存
为了提升查询和计算的效率,缓存技术在其中扮演着至关重要的角色。TDengine TSDB 在查询和计算的整个过程中充分利用了缓存技术,以优化系统性能。
在 TDengine TSDB 中,缓存被广泛应用于各个阶段,包括数据存储、查询优化、执行计划生成以及数据检索等。通过缓存热点数据和计算结果,TDengine TSDB 能够显著减少对底层存储系统的访问次数,降低计算开销,从而提高整体查询和计算效率。
此外,TDengine TSDB 的缓存机制还具备智能化的特点,能够根据数据访问模式和系统负载情况动态调整缓存策略。这使得 TDengine TSDB 在面对复杂多变的查询需求时,仍能保持良好的性能表现。
缓存的数据类型
缓存的数据类型分为如下 4 种。
- 元数据(database、table meta、stable vgroup)。
- 连接数据(rpc session、http session)。
- 时序数据(buffer pool、multilevel storage)。
- 最新数据(last、last_row)。
缓存方案
TDengine TSDB 针对不同类型的缓存对象采用了相应的缓存管理策略。对于元数据、RPC 对象和查询对象,TDengine TSDB 采用了哈希缓存的方式进行管理。这种缓存管理方式通过一个列表来管理,列表中的每个元素都是一个缓存结构,包含了缓存信息、哈希表、垃圾回收链表、统计信息、锁和刷新频率等关键信息。
为了确保缓存的有效性和系统性能,TDengine TSDB 还通过刷新线程定时检测缓存列表中的过期数据,并将过期数据删除。这种定期清理机制有助于避免缓存中存储过多无用数据,降低系统资源消耗,同时保持缓存数据的实时性和准确性。缓存方案下图所示:
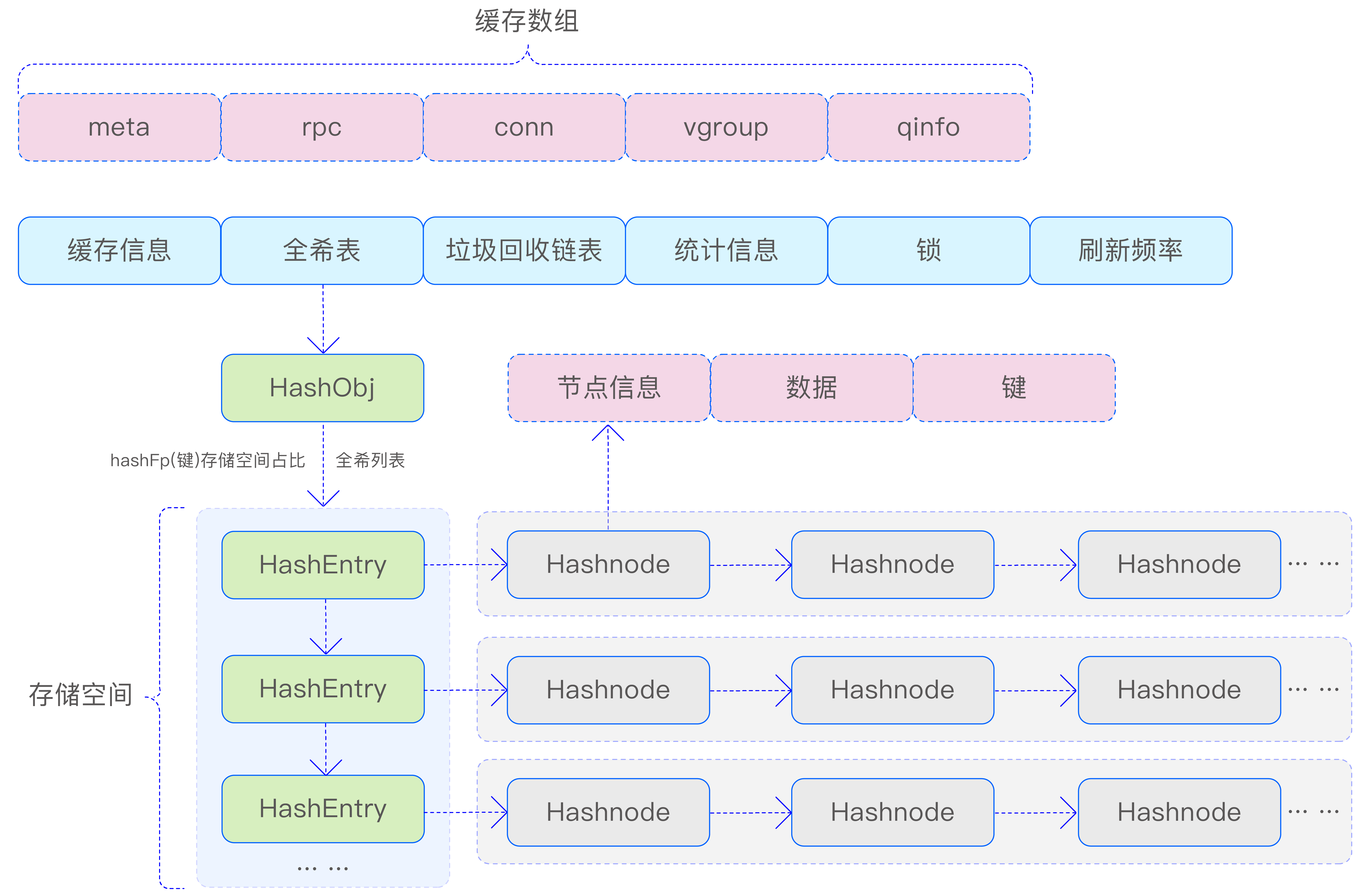
- 元数据缓存(meta data):包括数据库、超级表、用户、节点、视图、虚拟节点等信息,以及表的 schema 和其所在虚拟节点的映射关系。通过在 taosc 缓存元数据可以避免频繁地向 mnode/vnode 请求元数据。taosc 对元数据的缓存采用固定大小的缓存空间,先到先得,直到缓存空间用完。当缓存空间用完时,缓存会被进行部分淘汰处理,用来缓存新进请求所需要的元数据。
- 时序数据缓存(time series data):时序数据首先被缓存在 vnode 的内存中,以 skipList 形式组织,当达到落盘条件后,将时序数据进行压缩,写入数据存储文件中,并从缓存中清除。
- 最新数据缓存(last/last_row):对时序数据中的最新数据进行缓存,可以提高最新数据的查询效率。最新数据以子表为单元组织成 KV 形式,其中,K 是子表 ID,V 是该子表中每列的最后一个非 NULL 以及最新的一行数据。










