taosX 参考手册
taosX 是 TDengine TSDB Enterprise 中的一个核心组件,提供零代码数据接入的能力,taosX 支持两种运行模式:服务模式和命令行模式。本节讲述如何以这两种方式使用 taosX。要想使用 taosX 需要先安装 TDengine TSDB Enterprise 安装包。
命令行模式
命令行格式
taosX 的命令行参数格式如下
taosx -f <from-DSN> -t <to-DSN> <其它参数>
taosX 的命令行参数分为三个主要部分:
-f指定数据源,即 Source DSN-t指定写入目标,即 Sink DSN- 其它参数
以下参数说明及示例中若无特殊说明 <content> 的格式均为占位符,使用时需要使用实际参数进行替换。
DSN (Data Source Name)
taosX 命令行模式使用 DSN 来表示一个数据源(来源或目的源),典型的 DSN 如下:
# url-like
<driver>[+<protocol>]://[[<username>:<password>@]<host>:<port>][/<object>][?<p1>=<v1>[&<p2>=<v2>]]
|------|------------|---|-----------|-----------|------|------|----------|-----------------------|
|driver| protocol | | username | password | host | port | object | params |
// url 示例
tmq+ws://root:taosdata@localhost:6030/db1?timeout=never
[] 中的数据都为可选参数。
- 不同的驱动 (driver) 拥有不同的参数。driver 包含如下选项:
- taos:使用查询接口从 TDengine TSDB 获取数据
- tmq:启用数据订阅从 TDengine TSDB 获取数据
- local:数据备份或恢复
- pi:启用 pi-connector 从 pi 数据库中获取数据
- opc:启用 opc-connector 从 opc-server 中获取数据
- mqtt:启用 mqtt-connector 获取 mqtt-broker 中的数据
- kafka:启用 Kafka 连接器从 Kafka Topics 中订阅消息写入
- influxdb:启用 influxdb 连接器从 InfluxDB 获取数据
- csv:从 CSV 文件解析数据
- parquet:从 Parquet 文件读取数据
- +protocol 包含如下选项:
- +ws:当 driver 取值为 taos 或 tmq 时使用,表示使用 rest 获取数据。不使用 +ws 则表示使用原生连接获取数据,此时需要 taosx 所在的服务器安装 taosc。
- +ua:当 driver 取值为 opc 时使用,表示采集的数据的 opc-server 为 opc-ua
- +da:当 driver 取值为 opc 时使用,表示采集的数据的 opc-server 为 opc-da
- host:port 表示数据源的地址和端口。
- object 表示具体的数据源,可以是 TDengine TSDB 的数据库、超级表、表,也可以是本地备份文件的路径,也可以是对应数据源服务器中的数据库。
- username 和 password 表示该数据源的用户名和密码。
- params 代表了 dsn 的参数。
其它参数
- --jobs
<number>指定任务并发数,仅支持 tmq 任务 - -v 用于指定 taosx 的日志级别,-v 表示启用 info 级别日志,-vv 对应 debug,-vvv 对应 trace
使用举例
用户及权限信息导入导出
从集群 A 导出用户名、密码、权限和白名单信息到集群 B:
taosx privileges -f "taos://root:taosdata@hostA:6030" \
-t "taos+ws://root:password@hostB:6041"
从集群 A 导出用户名、密码、权限和白名单信息到 JSON 文件:
taosx privileges -f "taos+ws://root:taosdata@localhost:6041" \
-o ./user-pass-privileges-backup.json
从导出的 JSON 文件中恢复到本机:
taosx privileges -i ./user-pass-privileges-backup.json -t "taos:///"
可用参数列表:
| 参数 | 说明 |
|---|---|
| -u | 包含用户基本信息(密码、是否启用等) |
| -p | 包含权限信息 |
| -w | 包含白名单信息 |
当 -u/-p 参数应用时,将仅包含指定的信息,不带参数时,表示所有信息(用户名、密码、权限和白名单)。
-w 参数不能单独使用,当其与 -u 一起使用时才有效(单独使用 -u 将不包含白名单)。
从旧版本迁移数据
- 同步历史数据
同步整个库:
taosx run -f 'taos://root:taosdata@localhost:6030/db1' -t 'taos:///db2' -v
同步指定超级表:
taosx run \
-f 'taos://root:taosdata@localhost:6030/db1?stables=meters' \
-t 'taos:///db2' -v
同步子表或普通表,支持 {stable}.{table} 指定超级表的子表,或直接指定表名 {table}
taosx run \
-f 'taos://root:taosdata@localhost:6030/db1?tables=meters.d0,d1,table1' \
-t 'taos:///db2' -v
- 同步指定时间区间数据 (使用 RFC3339 时间格式,注意带时区 ):
taosx run -f 'taos:///db1?start=2022-10-10T00:00:00Z' -t 'taos:///db2' -v
- 持续同步,
restro指定同步最近 5m 中的数据,并同步新的数据,示例中每 1s 检查一次,excursion表示允许 500ms 的延时或乱序数据
taosx run \
-f 'taos:///db1?mode=realtime&restro=5m&interval=1s&excursion=500ms' \
-t 'taos:///db2' -v
- 同步历史数据 + 实时数据:
taosx run -f 'taos:///db1?mode=all' -t 'taos:///db2' -v
- 通过 --transform 或 -T 配置数据同步(仅支持 2.6 到 3.0 以及 3.0 之间同步)过程中对于表名及表字段的一些操作。暂无法通过 Explorer 进行设置。配置说明如下:
1.AddTag,为表添加 TAG。设置示例:-T add-tag:<tag1>=<value1>。
2.表重命名:
2.1 重命名表限定
2.1.1 RenameTable:对所有符合条件的表进行重命名。
2.1.2 RenameChildTable:对所有符合条件的子表进行重命名。
2.1.3 RenameSuperTable:对所有符合条件的超级表进行重命名。
2.2 重命名方式
2.2.1 Prefix:添加前缀。
2.2.2 Suffix:添加后缀。
2.2.3 Template:模板方式。
2.2.4 ReplaceWithRegex:正则替换。taosx 1.1.0 新增。
重命名配置方式:
<表限定>:<重命名方式>:<重命名值>
使用示例:
1.为所有表添加前缀 <prefix>
--transform rename-table:prefix:<prefix>
2.为符合条件的表替换前缀:prefix1 替换为 prefix2,以下示例中的 <> 为正则表达式的不再是占位符。
-T rename-child-table:replace_with_regex:^prefix1(?<old>)::prefix2_$old
示例说明:^prefix1(?<old>) 为正则表达式,该表达式会匹配表名中包含以 prefix1 开始的表名并将后缀部分记录为 old,prefix2$old 则会使用 prefix2 与 old 进行替换。注意:两部分使用关键字符 :: 进行分隔,所以需要保证正则表达式中不能包含该字符。
若有更复杂的替换需求请参考:https://docs.rs/regex/latest/regex/#example-replacement-with-named-capture-groups 或咨询 taosx 开发人员。
3. 使用 CSV 映射文件进行表重命名:以下示例使用 map.csv 文件进行表重命名
`-T rename-child-table:map:@./map.csv`
CSV 文件 `./map.csv` 格式如下:
name1,newname1
name2,newname2
需要注意的是:当迁移两端版本不一致,且使用原生连接时,需要在 DSN 中指定 libraryPath,如: taos:///db1?libraryPath=./libtaos.so
导入 CSV 文件数据
基本用法如下:
taosx run -f csv:./meters/meters.csv.gz \
--parser '@./meters/meters.json' \
-t taos:///csv1 -qq
以电表数据为例,CSV 文件如下:
tbname,ts,current,voltage,phase,groupid,location
d4,2017-07-14T10:40:00+08:00,-2.598076,16,-0.866025,7,California.LosAngles
d4,2017-07-14T10:40:00.001+08:00,-2.623859,6,-0.87462,7,California.LosAngles
d4,2017-07-14T10:40:00.002+08:00,-2.648843,2,-0.862948,7,California.LosAngles
d4,2017-07-14T10:40:00.003+08:00,-2.673019,16,-0.891006,7,California.LosAngles
d4,2017-07-14T10:40:00.004+08:00,-2.696382,10,-0.898794,7,California.LosAngles
d4,2017-07-14T10:40:00.005+08:00,-2.718924,6,-0.886308,7,California.LosAngles
d4,2017-07-14T10:40:00.006+08:00,-2.740636,10,-0.893545,7,California.LosAngles
--parser 用于设置入库参数,示例如下:
{
"parse": {
"ts": { "as": "TIMESTAMP(ms)" },
"current": { "as": "FLOAT" },
"voltage": { "as": "INT" },
"phase": { "as": "FLOAT" },
"groupid": { "as": "INT" },
"location": { "as": "VARCHAR(24)" }
},
"model": {
"name": "${tbname}",
"using": "meters",
"tags": ["groupid", "location"],
"columns": ["ts", "current", "voltage", "phase"]
}
}
它将从 ./meters/meters.csv.gz(一个 gzip 压缩的 CSV 文件)导入数据到超级表 meters,每一行都插入到指定的表名 - ${tbname} 使用 CSV 内容中的 tbname 列作为表名(即在 JSON 解析器中的 .model.name)。
导入 ORC 文件数据
ORC 文件(Optimized Row Columnar)专为 Hadoop 和 Hive 设计,支持高压缩率和快速查询,适合存储大量结构化数据。taosX 支持读取 ORC 文件数据并导入 TDengine,用法如下:
taosx --from 'orc:/root/test.orc?batch_size=1000&projection=col1,col3,col4' \
--parser '@parser.json' \
--to 'taos+http://localhost:6041/test'
--from/-f参数指定读取的 ORC 文件地址。batch_size表示一次读取的数据量,默认 1000 条。projection指定要读取的列,本例中表示读取col1,col3,col4这三列,也可以按照索引指定读取的列,如projection=1,3,4表示读取第 1,3,4 列,不指定此参数默认读取所有列。--parser用于设置数据处理配置和入库参数映射配置,同上面的 CSV 数据源。--to/-t参数指定写入的目标数据库,本例中表示写入test数据库。
TMQ 订阅数据发布到 MQTT
基本用法
taosx run -f "tmq+ws://username:password@ip:port/topic?param=value..." -t "mqtt://ip:port?param=value..."
其中 -f 指定 TMQ 订阅的 DSN,-t 指定 MQTT broker 的 DSN。
TMQ DSN 参数:
username: 数据库用户名。password: 数据库密码。ip和port: 数据库连接使用的 IP 和端口。topic: TMQ 订阅的 topic 名称。with.meta: 是否同步元数据,如创建表,删除表,修改表,删除数据等操作,默认值为false表示不同步元数据。with.meta.delete: 是否同步元数据中的删除数据事件,此参数仅当with.meta参数启用时有效。with.meta.drop: 是否同步元数据中的删除表事件,此参数仅当with.meta参数启用时有效。group.id: TMQ 订阅参数,必填项,订阅的组 ID。client.id: TMQ 订阅参数,选填项,订阅的客户端 ID。auto.offset.reset: TMQ 订阅参数,订阅的起始位置。experimental.snapshot.enable: TMQ 订阅参数,如启用,可以同步已经落盘到 TSDB 时序数据存储文件中(即不在 WAL 中)的数据。如关闭,则只同步尚未落盘(即保存在 WAL 中)的数据。
更多 TMQ 订阅时的所有参数,详见 数据订阅
MQTT DSN 参数:
ip: MQTT broker 的 IP 地址。port: MQTT broker 的 端口。version: MQTT 协议版本,必填项,可选值 3.1/3.1.1/5.0。qos: MQTT QoS 服务质量,默认值 0。client_id: MQTT 客户端 ID,必填项,不同客户端的客户端 ID 必须不同。topic: 数据发布的 MQTT 目标 Topic,必填项。meta_topic: 元数据发布的目标 Topic,如果不指定,默认使用数据发布的 Topic。
在 MQTT 的 topic 和 meta_topic 中支持使用如下变量:
database: 消息来源的数据库名,元数据和数据均包含。tmq_topic: 消息来源的 TMQ 主题名,元数据和数据均包含。vgroup_id: 消息来源 vgroup ID,元数据和数据均包含。stable: 消息来源的超级表名称,仅创建超级表,创建子表,删除超级表的元数据消息包含。table: 消息来源的表名/子表名,仅创建子表/普通表,修改表,删除子表/普通表以及数据类型的消息包含。
注意: 如果 topic 中包含了消息中不存在的变量,则当前消息不会被处理,即不会被发布到 MQTT broker。
导入 Parquet 文件数据
基本用法如下:
taosx run -f parquet:/data/sensors.parquet -t taos:///iot_db -v
DSN 参数说明:
Parquet 数据源使用以下 DSN 格式:
parquet:<file_path1>[,<file_path2>...]?[batch_size=<size>][&projection=<columns>][&unprocessed_batches=<count>]
支持的参数:
| 参数名称 | 类型 | 必填 | 默认值 | 说明 |
|---|---|---|---|---|
| file_path | string | 是 | - | Parquet 文件路径,支持多个文件用逗号分隔 |
| batch_size | integer | 否 | 1000 | 每批读取的行数 |
| projection | string | 否 | all | 列投影,可以是列名或列索引(从 0 开始) |
| unprocessed_batches | integer | 否 | 64 | 允许的最大未处理批次数,用于背压控制 |
使用示例:
- 读取单个 Parquet 文件:
taosx run -f parquet:/data/sensors.parquet -t taos:///iot_db -v
- 读取多个 Parquet 文件:
taosx run -f 'parquet:/data/sensors_2024_01.parquet,/data/sensors_2024_02.parquet' \
-t taos:///iot_db -v
- 使用列投影(按列名):
taosx run -f 'parquet:/data/sensors.parquet?projection=ts,temperature,humidity' \
-t taos:///iot_db -v
- 使用列投影(按索引):
taosx run -f 'parquet:/data/sensors.parquet?projection=0,2,5' \
-t taos:///iot_db -v
- 自定义批量大小:
taosx run -f 'parquet:/data/large_file.parquet?batch_size=5000' \
-t taos:///iot_db -v
- 完整配置示例:
taosx run -f 'parquet:/data/sensors.parquet?batch_size=2000&projection=ts,device_id,temperature&unprocessed_batches=100' \
-t taos:///iot_db -v
数据类型映射:
Parquet 数据类型会自动映射到 TDengine 数据类型:
| Parquet 类型 | TDengine 类型 |
|---|---|
| BOOLEAN | BOOL |
| INT32 | INT |
| INT64 | BIGINT |
| FLOAT | FLOAT |
| DOUBLE | DOUBLE |
| BYTE_ARRAY (UTF8) | NCHAR |
| BYTE_ARRAY (Binary) | BINARY |
| INT96 (Timestamp) | TIMESTAMP |
导出 SQL 查询结果到 Parquet 文件
taosx 支持将 TDengine 数据库的 SQL 查询结果导出为 Parquet 文件格式,方便数据分析和与其他系统集成。
基本用法如下:
taosx run -f "taos:///test?query=select tbname,* from test.meters" -t "parquet:./test.parquet"
参数说明:
-f指定数据源为 TDengine 数据库,通过query参数指定 SQL 查询语句-t指定导出目标为 Parquet 文件,包含文件路径
使用示例:
- 导出完整查询结果:
taosx run -f "taos:///test?query=select tbname,* from test.meters" \
-t "parquet:./test.parquet"
- 导出带有时间范围的查询结果:
taosx run -f "taos:///db1?query=select * from meters where ts >= '2024-01-01 00:00:00' and ts < '2024-02-01 00:00:00'" \
-t "parquet:./meters_202401.parquet"
- 导出聚合查询结果:
taosx run -f "taos:///test?query=select tbname, avg(voltage) as avg_voltage, max(current) as max_current from test.meters group by tbname" \
-t "parquet:./meters_stats.parquet"
- 使用 WebSocket 连接导出:
taosx run -f "taos+ws://root:taosdata@localhost:6041/test?query=select * from test.meters" \
-t "parquet:./test.parquet"
注意事项:
- SQL 查询语句需要进行 URL 编码,特别是包含特殊字符时
- 确保查询结果集大小适中,避免内存溢出
- TDengine 数据类型会自动映射为对应的 Parquet 数据类型
- 导出的 Parquet 文件可以被各种数据分析工具读取,如 Apache Spark、Pandas 等
服务模式
本节讲述如何以服务模式部署 taosX。以服务模式运行的 taosX,其各项功能需要通过 taosExplorer 上的图形界面来使用。
- 从 3.4.0.0 版本开始,taosX 使用 TSDB 作为元数据存储介质,不再使用 sqlite 存储元数据。不与旧版本兼容。
- 3.4.0.0 版本开始,taosX 需要先创建 XNODE,然后才能创建任务。参考 创建 XNODE 节点。
配置
taosX 支持通过配置文件进行配置。在 Linux 上,默认配置文件路径是 /etc/taos/taosx.toml,在 Windows 上,默认配置文件路径是 C:\\TDengine\\cfg\\taosx.toml,包含以下配置项:
plugins_home:外部数据源连接器所在目录。data_dir:数据文件存放目录。instanceId:当前 taosX 服务的实例 ID,如果同一台机器上启动了多个 taosX 实例,必须保证各个实例的实例 ID 互不相同。logs_home:日志文件存放目录,taosX日志文件的前缀为taosx.log,外部数据源有自己的日志文件名前缀。已弃用,请使用log.path代替。log_level:日志等级,可选级别包括error、warn、info、debug、trace,默认值为info。已弃用,请使用log.level代替。log_keep_days:日志的最大存储天数,taosX日志将按天划分为不同的文件。已弃用,请使用log.keepDays代替。jobs:程序默认运行时的线程数。默认线程数为当前服务器内核*2。serve.listen:是taosXREST API 监听地址,默认值为0.0.0.0:6050。支持 IPv6 协议的地址,同时支持多地址,多地址需保证端口一致,且使用英文逗号,作为分割。serve.ssl_cert:是 SSL/TLS 证书。serve.ssl_key:是 SSL/TLS 秘钥。serve.ssl_ca:是 SSL/TLS 根证书。serve.request_timeout:全局接口 API 超时时间。serve.grpc:是taosXgRPC 服务监听地址,默认值为0.0.0.0:6055。支持 IPv6 协议的地址,同时支持多地址,多地址需保证端口一致,且使用英文逗号,作为分割。rest_api_threads:rest api 服务的运行时线程数。默认线程数为当前服务器内核*2。grpc_threads:grpc 服务的运行时线程数。默认线程数为当前服务器内核*2。scheduler_threads:scheduler 任务服务的运行时线程数。默认线程数为当前服务器内核*2。monitor.fqdn:taosKeeper服务的 FQDN,没有默认值,置空则关闭监控功能。monitor.port:taosKeeper服务的端口,默认6043。monitor.interval:向taosKeeper发送指标的频率,默认为每 10 秒一次,只有 1 到 10 之间的值才有效。log.path:日志文件存放的目录。log.level:日志级别,可选值为 "error"、"warn"、"info"、"debug"、"trace"。log.compress:日志文件滚动后的文件是否进行压缩。log.rotationCount:日志文件目录下最多保留的文件数,超出数量的旧文件被删除。log.rotationSize:触发日志文件滚动的文件大小(单位为字节),当日志文件超出此大小后会生成一个新文件,新的日志会写入新文件。log.reservedDiskSize:日志所在磁盘停止写入日志的阈值(单位为字节),当磁盘剩余空间达到此大小后停止写入日志。log.keepDays:日志文件保存的天数,超过此天数的旧日志文件会被删除。log.watching:是否对日志文件中log.loggers配置内容的变更进行监听并尝试重载。log.loggers:指定模块的日志输出级别,格式为"modname" = "level",同时适配 tracing 库语法,可以根据modname[span{field=value}]=level,其中level为日志级别。
如下所示:
# data dir
#data_dir = "/var/lib/taos/taosx" # on linux/macOS
#data_dir = "C:\\TDengine\\data\\taosx" # on windows
# number of threads used for tokio workers, default to 0 (means cores * 2)
#jobs = 0
# enable OpenTelemetry tracing and metrics exporter
#otel = false
# server instance id
#
# The instanceId of each instance is unique on the host
# instanceId = 16
[serve]
# listen to ip:port address
#listen = "0.0.0.0:6050"
# TLS/SSL certificate
#ssl_cert = "/path/to/tls/server.pem"
# TLS/SSL certificate key
#ssl_key = "/path/to/tls/server.key"
# TLS/SSL CA certificate
#ssl_ca = "/path/to/tls/ca.pem"
# default global request timeout which unit is second. This parameter takes effect for certain interfaces that require a timeout setting
#request_timeout = 30
# GRPC listen address,use ip:port like `0.0.0.0:6055`.
#
# When use this in explorer, please set explorer grpc configuration to **Public** IP or
# FQDN with correct port, which might be changed exposing to Public network.
#
# - Example 1: "http://192.168.111.111:6055"
# - Example 2: "http://node1.company.domain:6055"
#
# Please also make sure the above address is not blocked if firewall is enabled.
#
#grpc = "0.0.0.0:6055"
# number of threads used for rest api service, default to 0 (means cores * 2)
#rest_api_threads = 0
# number of threads used for grpc service, default to 0 (means cores * 2)
#grpc_threads = 0
# number of threads used for scheduler service, default to 0 (means cores * 2)
#scheduler_threads = 0
[monitor]
# FQDN of taosKeeper service, no default value
#fqdn = "localhost"
# Port of taosKeeper service, default 6043
#port = 6043
# How often to send metrics to taosKeeper, default every 10 seconds. Only value from 1 to 10 is valid.
#interval = 10
# log configuration
[log]
# All log files are stored in this directory
#
#path = "/var/log/taos" # on linux/macOS
#path = "C:\\TDengine\\log" # on windows
# log filter level
#
#level = "info"
# Compress archived log files or not
#
#compress = false
# The number of log files retained by the current explorer server instance in the `path` directory
#
#rotationCount = 30
# Rotate when the log file reaches this size
#
#rotationSize = "1GB"
# Log downgrade when the remaining disk space reaches this size, only logging `ERROR` level logs
#
#reservedDiskSize = "1GB"
# The number of days log files are retained
#
#keepDays = 30
# Watching the configuration file for log.loggers changes, default to true.
#
#watching = true
# Customize the log output level of modules, and changes will be applied after modifying the file when log.watching is enabled
#
# ## Examples:
#
# crate = "error"
# crate::mod1::mod2 = "info"
# crate::span[field=value] = "warn"
#
[log.loggers]
#"actix_server::accept" = "warn"
#"taos::query" = "warn"
启动
Linux 系统上 taosX 可以通过 Systemd 命令启动:
systemctl start taosx
Windows 系统上通过系统管理工具 "Services" 找到 taosX 服务,然后启动它,或者在命令行工具(cmd.exe 或 PowerShell)中执行以下命令启动:
sc.exe start taosx
问题排查
- 修改
taosX日志级别
taosX 的默认日志级别为 info,要指定不同的级别,请修改配置文件,或使用以下命令行参数:
error:taosx serve -qqdebug:taosx serve -qinfo:taosx serve -vdebug:taosx serve -vvtrace:taosx serve -vvv
要在 taosX 作为服务运行时指定命令行参数,请参阅配置。
- 查看
taosX日志
您可以查看日志文件或使用 journalctl 命令来查看 taosX 的日志。
Linux 下 journalctl 查看日志的命令如下:
journalctl -u taosx [-f]
从旧版本升级
从 3.3.5.0/3.3.4.11 版本开始,不再在 systemd 服务文件预置 DATABASE_URL= 环境变量。如果在配置文件中使用了自定义 data_dir 参数,从旧版本升级后,必须将数据库文件从旧版本移动到自定义目录中。以 data_dir = "/path/to/data" 为例,执行以下命令:
mv /var/lib/taos/taosx/taosx.db* /path/to/data/
之后再重启服务(此行为仅影响 Linux 系统)。
taosX 监控指标
taosX 会将监控指标上报给 taosKeeper,这些监控指标会被 taosKeeper 写入监控数据库,默认是 log 库,可以在 taoskeeper 配置文件中修改。以下是这些监控指标的详细介绍。
taosX 服务
| 字段 | 描述 |
|---|---|
| sys_cpu_cores | 系统 CPU 核数 |
| sys_total_memory | 系统总内存,单位:字节 |
| sys_used_memory | 系统已用内存,单位:字节 |
| sys_available_memory | 系统可用内存,单位:字节 |
| process_uptime | taosX 运行时长,单位:秒 |
| process_id | taosX 进程 ID |
| running_tasks | taosX 当前执行任务数 |
| completed_tasks | taosX 进程在一个监控周期(比如 10s)内完成的任务数 |
| failed_tasks | taosX 进程在一个监控周期(比如 10s)内失败的任务数 |
| process_cpu_percent | taosX 进程占用 CPU 百分比,单位 % |
| process_memory_percent | taosX 进程占用内存百分比,单位 % |
| process_disk_read_bytes | taosX 进程在一个监控周期(比如 10s)内从硬盘读取的字节数的平均值,单位 bytes/s |
| process_disk_written_bytes | taosX 进程在一个监控周期(比如 10s)内写到硬盘的字节数的平均值,单位 bytres/s |
Agent
| 字段 | 描述 |
|---|---|
| sys_cpu_cores | 系统 CPU 核数 |
| sys_total_memory | 系统总内存,单位:字节 |
| sys_used_memory | 系统已用内存,单位:字节 |
| sys_available_memory | 系统可用内存,单位:字节 |
| process_uptime | agent 运行时长,单位:秒 |
| process_id | agent 进程 id |
| process_cpu_percent | agent 进程占用 CPU 百分比 |
| process_memory_percent | agent 进程占用内存百分比 |
| process_uptime | 进程启动时间,单位秒 |
| process_disk_read_bytes | agent 进程在一个监控周期(比如 10s)内从硬盘读取的字节数的平均值,单位 bytes/s |
| process_disk_written_bytes | agent 进程在一个监控周期(比如 10s)内写到硬盘的字节数的平均值,单位 bytes/s |
Connector
| 字段 | 描述 |
|---|---|
| process_id | connector 进程 id |
| process_uptime | 进程启动时间,单位秒 |
| process_cpu_percent | 进程占用 CPU 百分比,单位 % |
| process_memory_percent | 进程占用内存百分比,单位 % |
| process_disk_read_bytes | connector 进程在一个监控周期(比如 10s)内从硬盘读取的字节数的平均值,单位 bytes/s |
| process_disk_written_bytes | connector 进程在一个监控周期(比如 10s)内写到硬盘的字节数的平均值,单位 bytes/s |
taosX 通用数据源任务
| 字段 | 描述 |
|---|---|
| total_execute_time | 任务累计运行时间,单位毫秒 |
| total_written_rowsls | 成功写入 TDengine TSDB 的总行数(包括重复记录) |
| total_written_points | 累计写入成功点数 (等于数据块包含的行数乘以数据块包含的列数) |
| start_time | 任务启动时间 (每次重启任务会被重置) |
| written_rows | 本次运行此任务成功写入 TDengine TSDB 的总行数(包括重复记录) |
| written_points | 本次运行写入成功点数 (等于数据块包含的行数乘以数据块包含的列数) |
| execute_time | 任务本次运行时间,单位秒 |
taosX TDengine TSDB V2 任务
| 字段 | 描述 |
|---|---|
| read_concurrency | 并发读取数据源的数据 worker 数,也等于并发写入 TDengine TSDB 的 worker 数 |
| total_stables | 需要迁移的超级表数据数量 |
| total_updated_tags | 累计更新 tag 数 |
| total_created_tables | 累计创建子表数 |
| total_tables | 需要迁移的子表数量 |
| total_finished_tables | 完成数据迁移的子表数 (任务中断重启可能大于实际值) |
| total_success_blocks | 累计写入成功的数据块数 |
| finished_tables | 本次运行完成迁移子表数 |
| success_blocks | 本次写入成功的数据块数 |
| created_tables | 本次运行创建子表数 |
| updated_tags | 本次运行更新 tag 数 |
taosX TDengine TSDB V3 任务
| 字段 | 描述 |
|---|---|
| total_messages | 通过 TMQ 累计收到的消息总数 |
| total_messages_of_meta | 通过 TMQ 累计收到的 Meta 类型的消息总数 |
| total_messages_of_data | 通过 TMQ 累计收到的 Data 和 MetaData 类型的消息总数 |
| total_write_raw_fails | 累计写入 raw meta 失败的次数 |
| total_success_blocks | 累计写入成功的数据块数 |
| topics | 通过 TMQ 订阅的主题数 |
| consumers | TMQ 消费者数 |
| messages | 本次运行通过 TMQ 收到的消息总数 |
| messages_of_meta | 本次运行通过 TMQ 收到的 Meta 类型的消息总数 |
| messages_of_data | 本次运行通过 TMQ 收到的 Data 和 MetaData 类型的消息总数 |
| write_raw_fails | 本次运行写入 raw meta 失败的次数 |
| success_blocks | 本次写入成功的数据块数 |
taosX 其他数据源 任务
这些数据源包括:InfluxDB,OpenTSDB,OPC UA,OPC DA,PI,CSV,MQTT,AVEVA Historian 和 Kafka。
| 字段 | 描述 |
|---|---|
| total_received_batches | 通过 IPC Stream 收到的数据总批数 |
| total_processed_batches | 已经处理的批数 |
| total_processed_rows | 已经处理的总行数(等于每批包含数据行数之和) |
| total_inserted_sqls | 执行的 INSERT SQL 总条数 |
| total_failed_sqls | 执行失败的 INSERT SQL 总条数 |
| total_created_stables | 创建的超级表总数(可能大于实际值) |
| total_created_tables | 尝试创建子表总数 (可能大于实际值) |
| total_failed_rows | 写入失败的总行数 |
| total_failed_point | 写入失败的总点数 |
| total_written_blocks | 写入成功的 raw block 总数 |
| total_failed_blocks | 写入失败的 raw block 总数 |
| received_batches | 本次运行此任务通过 IPC Stream 收到的数据总批数 |
| processed_batches | 本次运行已处理批数 |
| processed_rows | 本次处理的总行数(等于包含数据的 batch 包含的数据行数之和) |
| received_records | 本次运行此任务通过 IPC Stream 收到的数据总行数 |
| inserted_sqls | 本次运行此任务执行的 INSERT SQL 总条数 |
| failed_sqls | 本次运行此任务执行失败的 INSERT SQL 总条数 |
| created_stables | 本次运行此任务尝试创建超级表数(可能大于实际值) |
| created_tables | 本次运行此任务尝试创建子表数 (可能大于实际值) |
| failed_rows | 本次运行此任务写入失败的行数 |
| failed_points | 本次运行此任务写入失败的点数 |
| written_blocks | 本次运行此任务写人成功的 raw block 数 |
| failed_blocks | 本次运行此任务写入失败的 raw block 数 |
Kafka 数据源相关指标
| 字段 | 描述 |
|---|---|
| kafka_consumers | 本次运行任务 Kafka 消费者数 |
| kafka_total_partitions | Kafka 主题总分区数 |
| kafka_consuming_partitions | 本次运行任务正在消费的分区数 |
| kafka_consumed_messages | 本次运行任务已经消费的消息数 |
| total_kafka_consumed_messages | 累计消费的消息总数 |
taosX 数据解析插件
接入 kafka / mqtt 消息中间件时,需要对原始数据进行解析,如果使用 json/regex 等模式解析器无法满足解析需求,同时 UDT(自定义解析脚本) 也无法满足性能要求时,可以自定义数据解析插件。
插件概述
taosX Parser 插件是一个要求用 C/Rust 语言开发的 C ABI 兼容动态库,该动态库要实现约定的 API 并编译为在 taosX 所在运行环境中能够正确运行的动态库,然后复制到约定位置由 taosX 在运行时加载,并在处理数据的 Parsing 阶段调用。
插件部署
完成插件开发后,编译环境需要和目标运行环境兼容,将编译好的插件动态库复制到插件目录下,taosX 启动后,系统首次使用插件时初始化加载插件。可以在 explorer 的 kafka 或者 mqtt 数据接入配置页面中,检查是否加载成功。如下图,如果加载成功,则在解析器选择列表中展示出来。
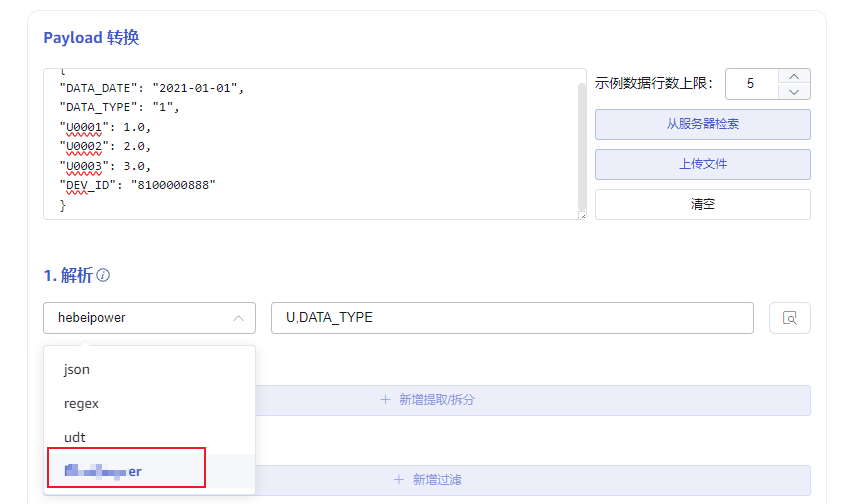
插件目录在 taosx.toml 配置文件中复用 plugins 配置,追加/parsers作为插件安装路径,默认值在 UNIX 环境下为 /usr/local/taos/plugins/parsers,在 Windows 下为 C:\TDengine\plugins\parsers。
插件 api 说明
1. 获取插件名称
获取插件名,用于前端显示。
函数签名:const char* parser_name()
返回值:字符串。
2. 获取插件版本
插件版本,方便问题定位。
函数签名:const char* parser_version()
返回值:字符串。
3. 配置解析器
将一个字符串参数解析为一个配置对象,仅插件内部使用。
函数签名:parser_resp_t parser_new(char* ctx, uint32_t len);
char* ctx:用户自定义配置字符串。
uint32_t len:该字符串的二进制长度(不含 \0)。
返回值:
struct parser_resp_t {
int e; // 0 if success.
void* p; // Success if contains.
}
当创建对象失败时,e 不为 0。
当创建成功时,e = 0,p 为解析器对象。
4. 解析数据
函数签名:
对输入 payload 进行解析,返回结果为 JSON 格式 [u8] 。返回的 JSON 将使用默认的 JSON 解析器进行完全解码(展开根数组和所有的对象)。
const char* parser_mutate(
void* parser,
const uint8_t* in_ptr, uint32_t in_len,
const void* uint8_t* out_ptr, uint32_t* out_len
);
void* parser:parser_new 生成的对象指针;
const uint8_t* in_ptr:输入 Payload 的指针;
uint32_t in_len:输入 Payload 的 bytes 长度(不含 \0);
const void* uint8_t* out_ptr:输出 JSON 字符串的指针(不含 \0)。当 out_ptr 指向为空时,表示输出为空。
uint32_t * out_len:输出 JSON 字符串长度。
返回值:当调用成功时,返回值为 NULL。
5. 释放解析器
释放解析器对象内存。
函数签名: void parser_free(void* parser);
void* parser:parser_new 生成的对象指针。










