OPC-UA
本节讲述如何通过 Explorer 界面创建数据迁移任务,从 OPC-UA 服务器同步数据到当前 TDengine TSDB 集群。
功能概述
OPC 是工业自动化领域和其他行业中安全可靠地交换数据的互操作标准之一。
OPC-UA 是经典 OPC 规范的下一代标准,是一个平台无关的面向服务的架构规范,集成了现有 OPC Classic 规范的所有功能,提供了一条迁移到更安全和可扩展解决方案的路径。
TDengine TSDB 可以高效地从 OPC-UA 服务器读取数据并将其写入 TDengine TSDB,以实现实时数据入库。
创建任务
1. 新增数据源
在数据写入页面中,点击 +新增数据源 按钮,进入新增数据源页面。

2. 配置基本信息
在 名称 中输入任务名称,例如针对环境温湿度监控的任务,取名为 environment-monitoring。
在 类型 下拉列表中选择 OPC-UA。
代理 是非必填项,如有需要,可以在下拉框中选择指定的代理,也可以先点击右侧的 +创建新的代理 按钮
在 目标数据库 下拉列表中选择一个目标数据库,也可以先点击右侧的 +创建数据库 按钮
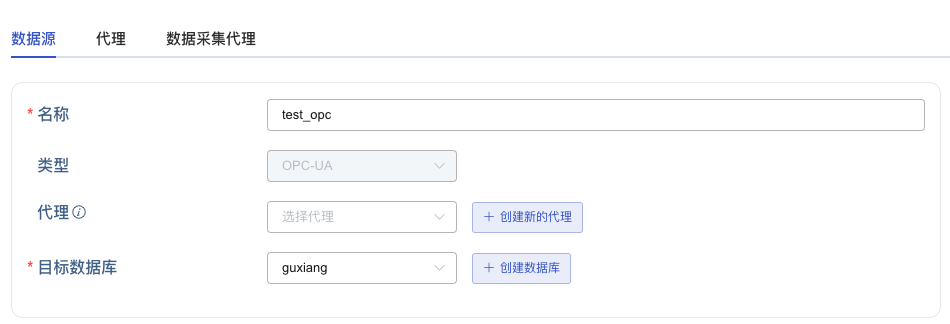
3. 配置连接信息
在 连接配置 区域填写 OPC-UA 服务地址,例如:127.0.0.1:5000,并配置数据传输安全模式,有三种安全模式可选:
- None:通信数据以明文形式传输。
- Sign:使用数字签名对通信数据进行验证,保护数据完整性。
- SignAndEncrypt:使用数字签名对通信数据进行验证,并使用加密算法对数据进行加密,以保证数据的完整性、真实性和保密性。
如果安全模式选择了 Sign 或者 SignAndEncrypt,则必须选择有效的安全策略。安全策略定义了如何实现安全模式中的加密和验证机制,包括使用的加密算法、密钥长度、数字证书等。可选的安全策略有:
- None:只能在安全模式为 None 时可选。
- Basic128Rsa15:使用 RSA 算法和 128 位的密钥长度对通信数据进行签名或加密。
- Basic256:使用 AES 算法和 256 位的密钥长度对通信数据进行签名或加密。
- Basic256Sha256:使用 AES 算法和 256 位的密钥长度,并使用 SHA-256 算法对数字签名进行加密。
- Aes128Sha256RsaOaep:使用 AES-128 算法进行通信数据的加解密,并使用 SHA-256 算法对数字签名进行加密,并使用 RSA 算法和 OAEP 模式用于加解密对称通信密钥。
- Aes256Sha256RsaPss:使用 AES-256 算法进行通信数据的加解密,并使用 SHA-256 算法对数字签名进行加密,并使用 RSA 算法和 PSS 模式用于加解密对称通信密钥。
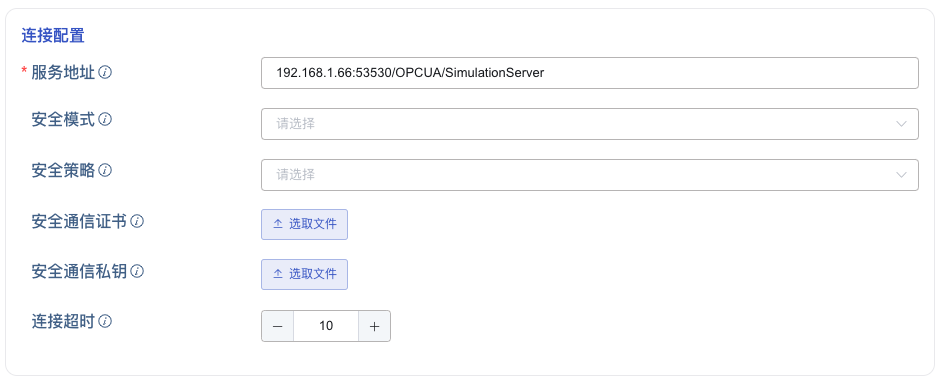
4. 选择认证方式
如下图所示,切换 tab 可选择不同的认证方式,可选的认证方式有:
- 匿名
- 用户名
- 证书访问:可以和安全通信证书相同,也可以用不同的证书。
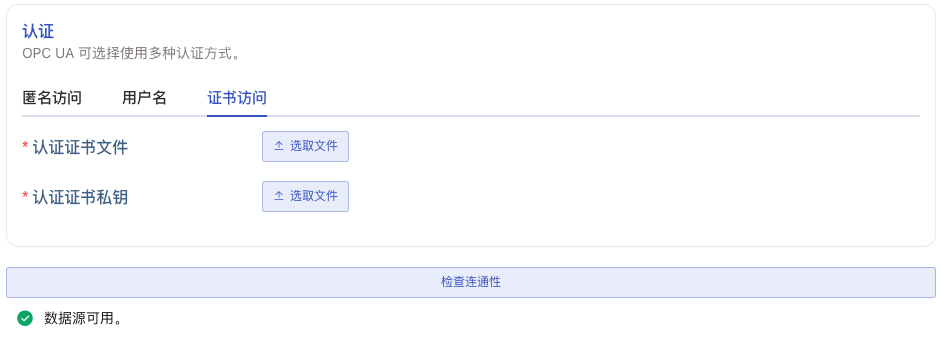
配置好连接属性和认证方式后,点击 连通性检查 按钮,检查数据源是否可用。如果使用安全通信证书或认证证书,则证书必须在 OPC UA 服务端被信任,否则依然无法通过。
5. 配置点位集
点位集 可选择使用 CSV 文件模板或 选择所有点位。
5.1. 上传 CSV 配置文件
您可以下载 CSV 空模板并按模板配置点位信息,然后上传 CSV 配置文件来配置点位;或者根据所配置的筛选条件下载数据点位,并以 CSV 模板所制定的格式下载。
CSV 文件有如下规则:
- 文件编码
用户上传的 CSV 文件的编码格式必须为以下格式中的一种:
(1) UTF-8 with BOM
(2) UTF-8(即:UTF-8 without BOM)
- Header 配置规则
Header 是 CSV 文件的第一行,规则如下:
(1) CSV 的 Header 中可以配置以下列:
| 序号 | 列名 | 描述 | 是否必填 | 默认行为 |
|---|---|---|---|---|
| 1 | point_id | 数据点位在 OPC UA 服务器上的 id | 是 | 无 |
| 2 | stable | 数据点位在 TDengine TSDB 中对应的超级表 | 是 | 无 |
| 3 | tbname | 数据点位在 TDengine TSDB 中对应的子表 | 是 | 无 |
| 4 | enable | 是否采集该点位的数据 | 否 | 使用统一的默认值1作为 enable 的值 |
| 5 | value_col | 数据点位采集值在 TDengine TSDB 中对应的列名 | 否 | 使用统一的默认值val 作为 value_col 的值 |
| 6 | value_transform | 数据点位采集值在 taosX 中执行的变换函数 | 否 | 统一不进行采集值的 transform |
| 7 | type | 数据点位采集值的数据类型 | 否 | 统一使用采集值的原始类型作为 TDengine TSDB 中的数据类型 |
| 8 | quality_col | 数据点位采集值质量在 TDengine TSDB 中对应的列名 | 否 | 统一不在 TDengine TSDB 添加 quality 列 |
| 9 | ts_col | 数据点位的原始时间戳在 TDengine TSDB 中对应的时间戳列 | 否 | ts_col,request_ts,received_ts 这 3 列,当有 2 列以上存在时,以最左侧的列作为 TDengine TSDB 中的主键。 |
| 10 | request_ts_col | 请求到该点位采集值时的时间戳在 TDengine TSDB 中对应的时间戳列 | 否 | ts_col,request_ts,received_ts 这 3 列,当有 2 列以上存在时,以最左侧的列作为 TDengine TSDB 中的主键。 |
| 11 | received_ts_col | 接收到该点位采集值时的时间戳在 TDengine TSDB 中对应的时间戳列 | 否 | ts_col,request_ts,received_ts 这 3 列,当有 2 列以上存在时,以最左侧的列作为 TDengine TSDB 中的主键。 |
| 12 | ts_transform | 数据点位时间戳在 taosX 中执行的变换函数 | 否 | 统一不进行数据点位原始时间戳的 transform |
| 13 | request_ts_transform | 数据点位接收时间戳在 taosX 中执行的变换函数 | 否 | 统一不进行数据点位接收时间戳的 transform |
| 14 | received_ts_transform | 数据点位接收时间戳在 taosX 中执行的变换函数 | 否 | 统一不进行数据点位接收时间戳的 transform |
| 15 | tag::VARCHAR(200)::name | 数据点位在 TDengine TSDB 中对应的 Tag 列。其中tag 为保留关键字,表示该列为一个 tag 列;VARCHAR(200) 表示该 tag 的类型,也可以是其它合法的类型;name 是该 tag 的实际名称。 | 否 | 配置 1 个以上的 tag 列,则使用配置的 tag 列;没有配置任何 tag 列,且 stable 在 TDengine TSDB 中存在,使用 TDengine TSDB 中的 stable 的 tag;没有配置任何 tag 列,且 stable 在 TDengine TSDB 中不存在,则默认自动添加以下 2 个 tag 列:tag::VARCHAR(256)::point_id 和 tag::VARCHAR(256)::point_name |
(2) CSV Header 中,不能有重复的列;
(3) CSV Header 中,类似tag::VARCHAR(200)::name这样的列可以配置多个,对应 TDengine TSDB 中的多个 Tag,但 Tag 的名称不能重复。
(4) CSV Header 中,列的顺序不影响 CSV 文件校验规则;
(5) CSV Header 中,可以配置不在上表中的列,例如:序号,这些列会被自动忽略。
- Row 配置规则
CSV 文件中的每个 Row 配置一个 OPC 数据点位。Row 的规则如下:
(1) 与 Header 中的列有如下对应关系
| 序号 | Header 中的列 | 值的类型 | 值的范围 | 是否必填 | 默认值 |
|---|---|---|---|---|---|
| 1 | point_id | String | 类似ns=3;i=1005这样的字符串,要满足 OPC UA 的 ID 的规范,即:包含 ns 和 id 部分 | 是 | |
| 2 | enable | int | 0:不采集该点位,且在 OPC DataIn 任务开始前,删除 TDengine TSDB 中点位对应的子表;1:采集该点位,在 OPC DataIn 任务开始前,不删除子表。 | 否 | 1 |
| 3 | stable | String | 符合 TDengine TSDB 超级表命名规范的任何字符串;如果存在特殊字符.,使用下划线替换如果存在{type},则:CSV 文件的 type 不为空,使用 type 的值进行替换 CSV 文件的 type 为空,使用采集值的原始类型进行替换 | 是 | |
| 4 | tbname | String | 符合 TDengine TSDB 子表命名规范的任何字符串;如果存在特殊字符.,使用下划线替换对于 OPC UA:如果存在{ns},使用 point_id 中的 ns 替换如果存在{id},使用 point_id 中的 id 替换对于 OPC DA:如果存在{tag_name},使用 tag_name 替换 | 是 | |
| 5 | value_col | String | 符合 TDengine TSDB 命名规范的列名 | 否 | val |
| 6 | value_transform | String | 符合 Rhai 引擎的计算表达式,例如:(val + 10) / 1000 * 2.0,log(val) + 10等; | 否 | None |
| 7 | type | String | 支持类型包括:b/bool/i8/tinyint/i16/small/inti32/int/i64/bigint/u8/tinyint unsigned/u16/smallint unsigned/u32/int unsigned/u64/bigint unsigned/f32/float/f64/double/timestamp/timestamp(ms)/timestamp(us)/timestamp(ns)/json | 否 | 数据点位采集值的原始类型 |
| 8 | quality_col | String | 符合 TDengine TSDB 命名规范的列名 | 否 | None |
| 9 | ts_col | String | 符合 TDengine TSDB 命名规范的列名 | 否 | ts |
| 10 | request_ts_col | String | 符合 TDengine TSDB 命名规范的列名 | 否 | rts |
| 11 | received_ts_col | String | 符合 TDengine TSDB 命名规范的列名 | 否 | rts |
| 12 | ts_transform | String | 支持 +、-、、/、% 操作符,例如:ts / 1000 1000,将一个 ms 单位的时间戳的最后 3 位置为 0;ts + 8 3600 1000,将一个 ms 精度的时间戳,增加 8 小时;ts - 8 3600 1000,将一个 ms 精度的时间戳,减去 8 小时; | 否 | None |
| 13 | request_ts_transform | String | 支持 +、-、、/、% 操作符,例如:qts / 1000 1000,将一个 ms 单位的时间戳的最后 3 位置为 0;qts + 8 3600 1000,将一个 ms 精度的时间戳,增加 8 小时;qts - 8 3600 1000,将一个 ms 精度的时间戳,减去 8 小时; | 否 | None |
| 14 | received_ts_transform | String | 支持 +、-、、/、% 操作符,例如:rts / 1000 1000,将一个 ms 单位的时间戳的最后 3 位置为 0;rts + 8 3600 1000,将一个 ms 精度的时间戳,增加 8 小时;rts - 8 3600 1000,将一个 ms 精度的时间戳,减去 8 小时; | 否 | None |
| 15 | tag::VARCHAR(200)::name | String | tag 里的值,当 tag 的类型是 VARCHAR 时,可以是中文 | 否 | NULL |
(2) point_id 在整个 DataIn 任务中是唯一的,即:在一个 OPC DataIn 任务中,一个数据点位只能被写入到 TDengine TSDB 的一张子表。如果需要将一个数据点位写入多张子表,需要建多个 OPC DataIn 任务;
(3) 当 point_id 不同,但 tbname 相同时,value_col 必须不同。这种配置能够将不同数据类型的多个点位的数据写入同一张子表中不同的列。这种方式对应“OPC 数据入 TDengine TSDB 宽表”的使用场景。
- 其他规则
(1) 如果 Header 和 Row 的列数不一致,校验失败,提示用户不满足要求的行号;
(2) Header 在首行,且不能为空;
(3) 至少有一个数据点;
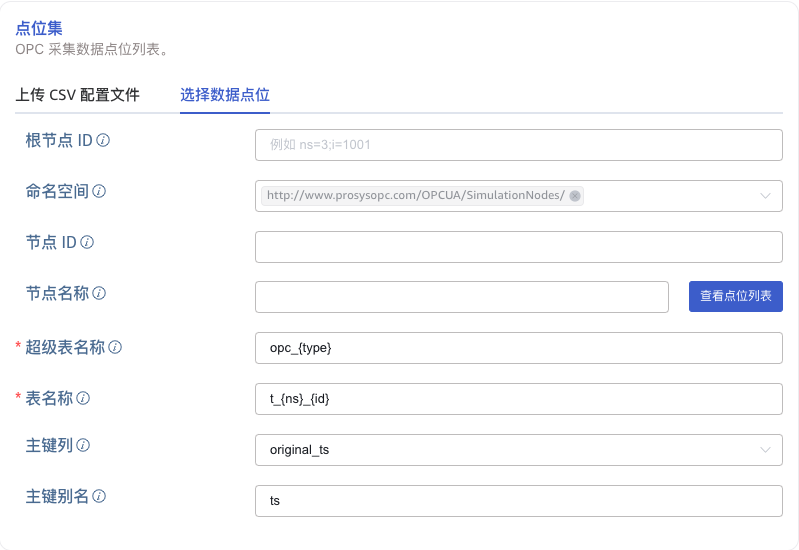
5.2. 选择数据点位
可以通过配置 根节点 ID、命名空间、节点 ID、节点名称 等条件,对点位进行筛选。
通过配置 超级表名、表名称,指定数据要写入的超级表、子表。
配置主键列,选择 origin_ts 表示使用 OPC 点位数据的原始时间戳作 TDengine TSDB 中的主键;选择 request_ts 表示使用数据的请求时间戳作 TDengine TSDB 中的主键;选择 received_ts 表示使用数据的接收时间戳作 TDengine TSDB 中的主键。配置主键别名,指定 TDengine TSDB 时间戳列的名称。
6. 采集配置
在采集配置中,配置当前任务的采集模式、采集间隔、采集超时等选项。
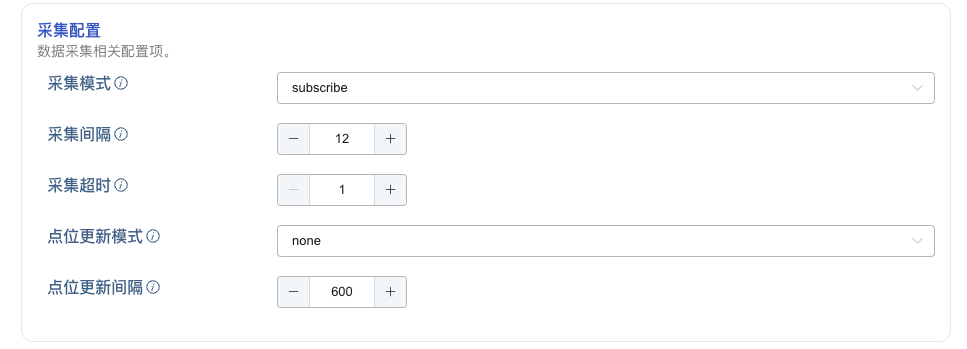
如上图所示,其中:
- 采集模式:可使用
subscribe或observe模式。subscribe:订阅模式,变更时上报数据并写入 TDengine TSDB。observe:按照采集间隔时长,轮询读取点位最新值并写入 TDengine TSDB。
- 采集间隔:默认为 10 秒,数据点位采集间隔,从上次采集数据结束后开始计时,轮询读取点位最新值并写入 TDengine TSDB。仅在 采集模式 为
observe时可配置。 - 采集超时:向 OPC 服务器读取点位数据时如果超过设定时间未返回数据,则读取失败,默认为 10 秒。仅在 采集模式 为
observe时可配置。
当 点位集 中使用 选择数据点位 方式时,采集配置中可以配置 点位更新模式 和 点位更新间隔 来启用动态点位更新。动态点位更新 是指,在任务运行期间,OPC Server 增加或删除了点位后,符合条件的点位会自动添加到当前任务中,不需要重启 OPC 任务。
- 点位更新模式:可选择
None、Append、Update三种。- None:不开启动态点位更新;
- Append:开启动态点位更新,但只追加;
- Update:开启动态点位更新,追加或删除;
- 点位更新间隔:在“点位更新模式”为
Append和Update时生效。单位:秒,默认值是 600,最小值:60,最大值:2147483647。
7. 高级选项
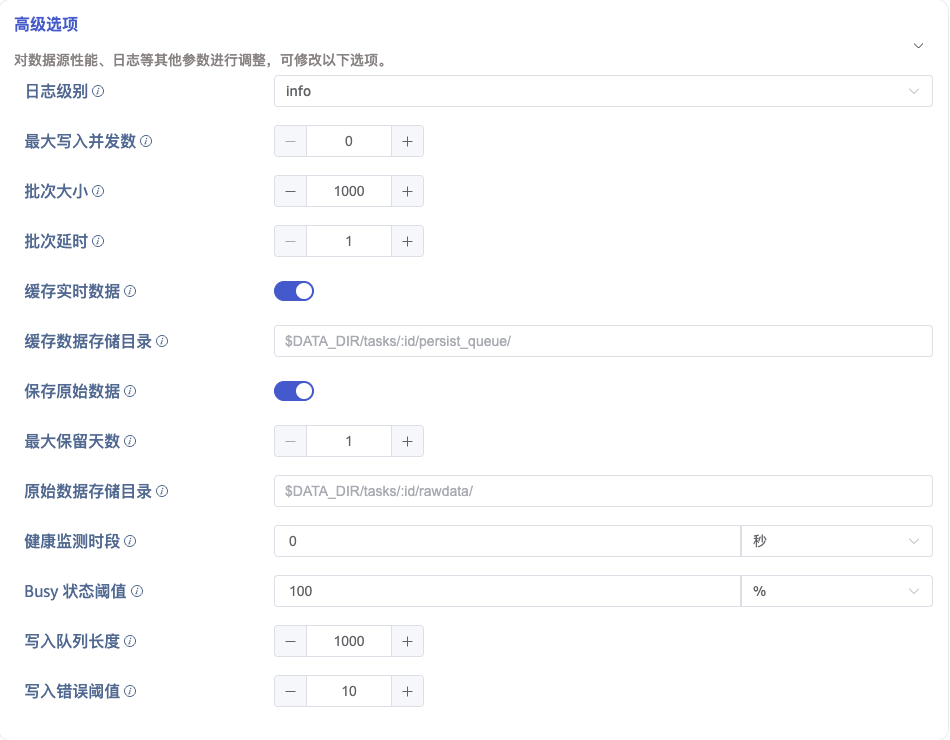
如上图所示,配置高级选项对性能、日志等进行更加详尽的优化。
日志级别 默认为 info,可选项有 error、warn、info、debug、trace。
在 最大写入并发数 中设置写入 taosX 的最大并发数限制。默认值:0,表示 auto,自动配置并发数。
在 批次大小 中设置每次写入的批次大小,即:单次发送的最大消息数量。
在 批次延时 中设置单次发送最大延时(单位为秒),当超时结束时,只要有数据,即使不满足批次大小,也立即发送。
当 缓存实时数据 选项开启时,MQTT 消费的数据会先存入本地文件中,本地文件的数据会被后台任务持续读出并发送给下游处理。当 MQTT 数据流量巨大,下游无法及时处理造成数据消费卡顿导致数据丢弃时使用,即用于流量削峰,当数据消费完毕后,会自动清理文件。此功能默认关闭。
在 缓存数据存储目录 中可填写数据缓存的存储目录路径,默认为 taosX 启动时配置的数据目录,也可以填写自定义目录。此选项仅在 缓存实时数据 选项开启时有效。
在 保存原始数据 中选择是否保存原始数据。默认值:否。
当保存原始数据时,以下 2 个参数配置生效。
在 最大保留天数 中设置原始数据的最大保留天数。
在 原始数据存储目录 中设置原始数据保存路径。若使用 Agent,则存储路径指的是 Agent 所在服务器上路径,否则是 taosX 服务器上路径。路径中可使用占位符 $DATA_DIR 和 :id 作为路径中的一部分。
- Linux 平台,$DATA_DIR 为 /var/lib/taos/taosx,默认情况下存储路径为
/var/lib/taos/taosx/tasks/<task_id>/rawdata。 - Windows 平台, $DATA_DIR 为 C:\TDengine\data\taosx,默认情况下存储路径为
C:\TDengine\data\taosx\tasks\<task_id>\rawdata。
8. 创建完成
点击 提交 按钮,完成创建 OPC UA 到 TDengine TSDB 的数据同步任务,回到数据源列表页面可查看任务执行情况。
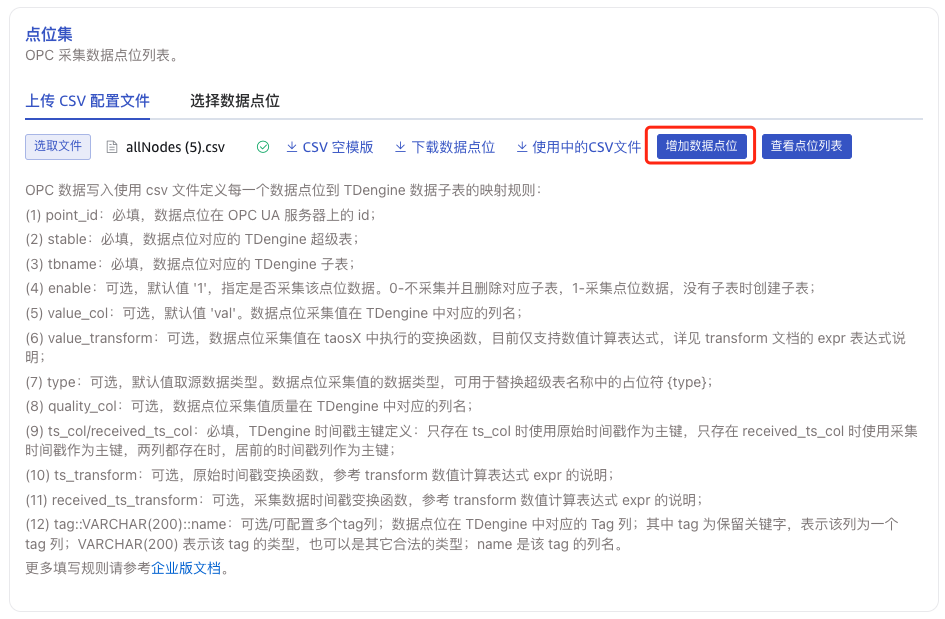
增加数据点位
在任务运行中,点击 编辑,点击 增加数据点位 按钮,追加数据点位到 CSV 文件中。
在弹出的表单中,填写数据点位的信息。
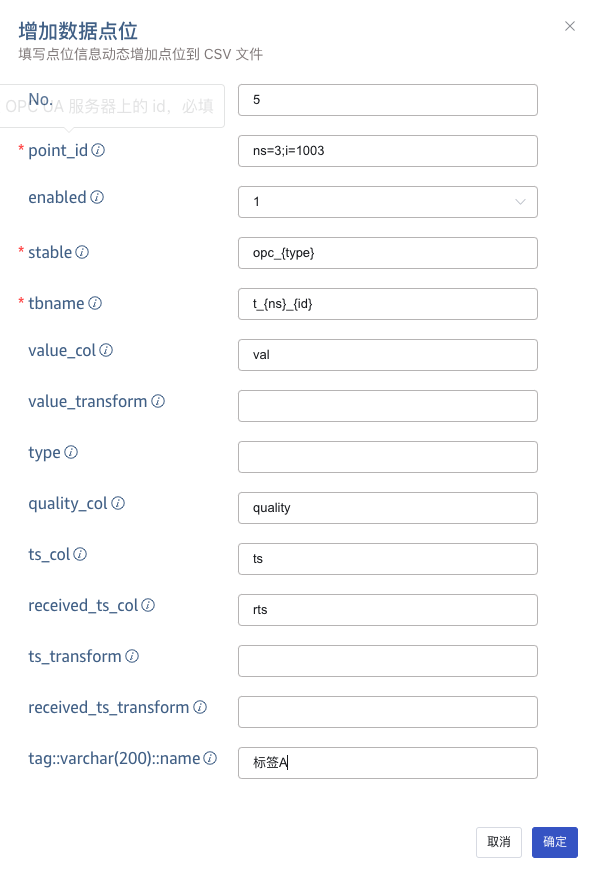
点击 确定 按钮,完成数据点位的追加。










