MySQL
本节讲述如何通过 Explorer 界面创建数据迁移任务,从 MySQL 迁移数据到当前 TDengine TSDB 集群。
功能概述
MySQL 是最流行的关系型数据库之一。很多系统都曾经或正在使用 MySQL 数据库存储物联网、工业互联网等设备上报的数据。但随着接入系统的设备量日益增长、用户对数据实时性反馈的要求也越来越高,MySQL 已经无法满足业务需求。从 TDengine TSDB 企业版 3.3.0.0 开始,TDengine TSDB 可以高效地从 MySQL 读取数据并将其写入 TDengine TSDB,以实现历史数据迁移或实时数据同步,解决业务面临的技术痛点。
创建任务
1. 新增数据源
在数据写入页面中点击左上角的 +新增数据源 按钮进入新增数据源页面,如下图所示:

2. 配置基本信息
在 名称 字段中输入任务名称,例如 test_mysql_01 。
选择 类型 下拉框中的 MySQL ,如下图所示(选择完成后页面中的字段会发生变化)。
代理 是非必填项,如有需要,可以在下拉框中选择指定的代理,也可以先点击右侧的 +创建新的代理 按钮创建一个新的代理。
目标数据库 是必填项,可以先点击右侧的 +创建数据库 按钮创建一个新的数据库。

3. 配置连接信息
在 连接配置 区域填写 源 MySQL 数据库的连接信息,如下图所示:

4. 配置认证信息
用户 输入源 MySQL 数据库的用户,该用户必须在该组织中拥有读取权限。
密码 输入源 MySQL 数据库中上方用户的登陆密码。

5. 配置连接选项
字符集 设置连接的字符集。默认字符集为 utf8mb4。MySQL 5.5.3 支持此功能。如果需要连接到旧版本,建议改为 utf8。 可选项有 utf8、utf8mb4、utf16、utf32、gbk、big5、latin1、ascii。
SSL 模式 设置是否与服务器协商安全 SSL TCP/IP 连接或以何种优先级进行协商。默认值是 PREFERRED。可选项有 DISABLED、PREFERRED、REQUIRED。

然后点击 检查连通性 按钮,用户可以点击此按钮检查上方填写的信息是否可以正常获取源 MySQL 数据库的数据。
6. 配置 SQL 查询
子表字段 用于拆分子表的字段,它是一条 select distinct 的 SQL 语句,查询指定字段组合的非重复项,通常与 transform 中的 tag 相对应:
此项配置主要为了解决数据迁移乱序问题,需要结合SQL 模板共同使用,否则不能达到预期效果,使用示例如下:
- 子表字段填写语句
select distinct col_name1, col_name2 from table,它表示使用源表中的字段 col_name1 与 col_name2 拆分目标超级表的子表- 在SQL 模板中添加子表字段占位符,例如
select * from table where ts >= ${start} and ts < ${end} and ${col_name1} and ${col_name2}中的${col_name1} and ${col_name2}部分- 在 transform 中配置
col_name1与col_name2两个 tag 映射
SQL 模板 用于查询的 SQL 语句模板,SQL 语句中必须包含时间范围条件,且开始时间和结束时间必须成对出现。SQL 语句模板中定义的时间范围由源数据库中的某个代表时间的列和下面定义的占位符组成。
SQL 使用不同的占位符表示不同的时间格式要求,具体有以下占位符格式:
${start}、${end}:表示 RFC3339 格式时间戳,如:2024-03-14T08:00:00+0800${start_no_tz}、${end_no_tz}: 表示不带时区的 RFC3339 字符串:2024-03-14T08:00:00${start_date}、${end_date}:表示仅日期,如:2024-03-14为了解决迁移数据乱序的问题,应在查询语句中添加排序条件,例如
order by ts asc。
起始时间 迁移数据的起始时间,此项为必填字段。
结束时间 迁移数据的结束时间,可留空。如果设置,则迁移任务执行到结束时间后,任务完成自动停止;如果留空,则持续同步实时数据,任务不会自动停止。
查询间隔 分段查询数据的时间间隔,默认 1 天。为了避免查询数据量过大,一次数据同步子任务会使用查询间隔分时间段查询数据。
延迟时长 与 查询间隔 配合使用。在实时同步数据场景中,为了避免延迟写入的数据丢失,每次同步任务会在时间间隔 + 延迟时长的时间点触发查询。例如:时间间隔为 3600s,延迟时长为 60 秒,那么查询任务会在 09:01 时触发查询源数据库中 08:00 - 09:00 时间段的数据。

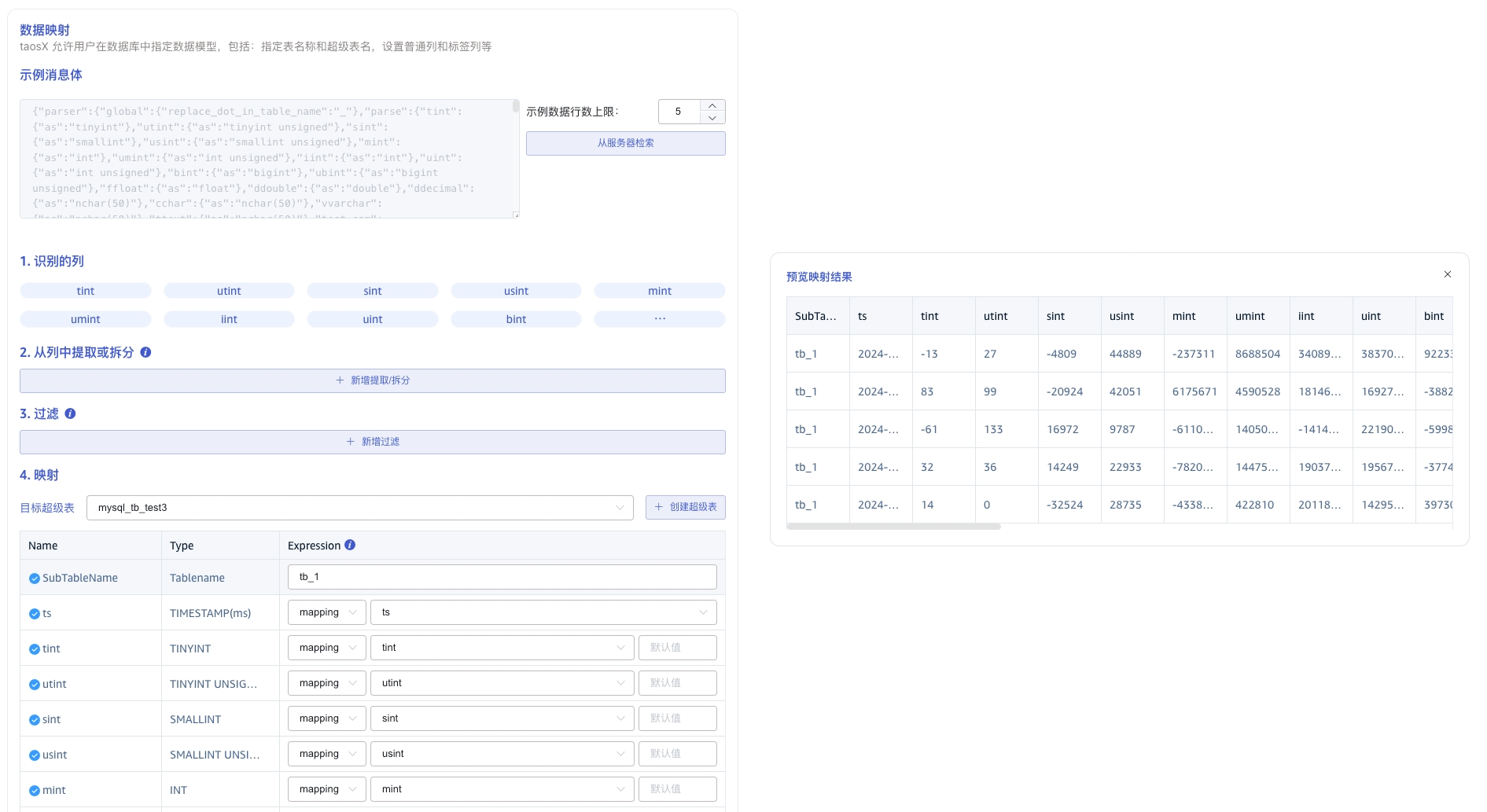
7. 配置数据映射
在 数据映射 区域填写数据映射相关的配置参数。
点击 从服务器检索 按钮,从 MySQL 服务器获取示例数据。
在 从列中提取或拆分 中填写从消息体中提取或拆分的字段,例如:将 vValue 字段拆分成 vValue_0 和 vValue_1 这 2 个字段,选择 split 提取器,separator 填写分割符 ,, number 填写 2。
在 过滤 中,填写过滤条件,例如:填写Value > 0,则只有 Value 大于 0 的数据才会被写入 TDengine TSDB。
在 映射 中,选择要映射到 TDengine TSDB 的超级表,以及映射到超级表的列。
点击 预览,可以查看映射的结果。
8. 配置高级选项
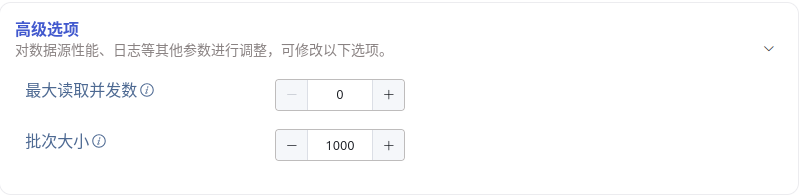
高级选项 区域是默认折叠的,点击右侧 > 可以展开,如下图所示:
最大读取并发数 数据源连接数或读取线程数限制,当默认参数不满足需要或需要调整资源使用量时修改此参数。
批次大小 单次发送的最大消息数或行数。默认是 10000。
9. 异常处理策略
异常处理策略区域是对数据异常时的处理策略进行配置,默认折叠的,点击右侧 > 可以展开,如下图所示:
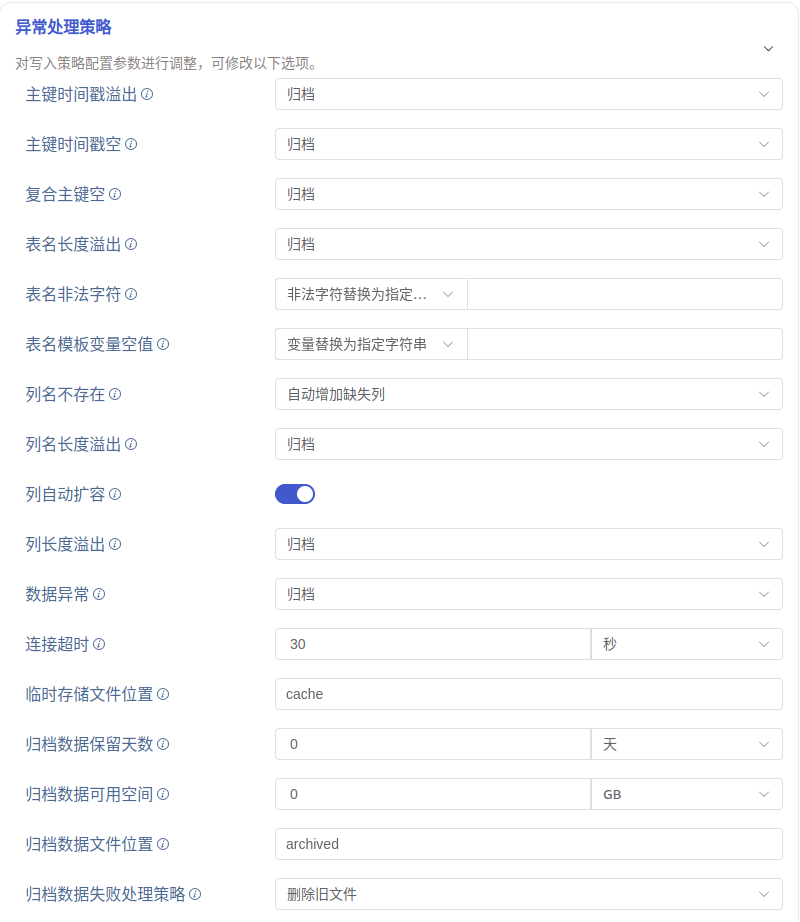
各异常项说明及相应可选处理策略如下:
通用处理策略说明:
归档:将异常数据写入归档文件(默认路径为${data_dir}/tasks/_id/.datetime),不写入目标库
丢弃:将异常数据忽略,不写入目标库
报错:任务报错
- 目标库连接超时 目标库连接失败,可选处理策略:归档、丢弃、报错、缓存
缓存:当目标库状态异常(连接错误或资源不足等情况)时写入缓存文件(默认路径为
${data_dir}/tasks/_id/.datetime),目标库恢复正常后重新入库 - 目标库不存在 写入报错目标库不存在,可选处理策略:归档、丢弃、报错
- 表不存在 写入报错表不存在,可选处理策略:归档、丢弃、报错、自动建表
自动建表:自动建表,建表成功后重试
- 主键时间戳溢出 检查数据中第一列时间戳是否在正确的时间范围内(now - keep1, now + 100y),可选处理策略:归档、丢弃、报错
- 主键时间戳空 检查数据中第一列时间戳是否为空,可选处理策略:归档、丢弃、报错、使用当前时间
使用当前时间:使用当前时间填充到空的时间戳字段中
- 复合主键空 写入报错复合主键空,可选处理策略:归档、丢弃、报错
- 表名长度溢出 检查子表表名的长度是否超出限制(最大 192 字符),可选处理策略:归档、丢弃、报错、截断、截断且归档
截断:截取原始表名的前 192 个字符作为新的表名
截断且归档:截取原始表名的前 192 个字符作为新的表名,并且将此行记录写入归档文件 - 表名非法字符 检查子表表名中是否包含特殊字符(符号
.等),可选处理策略:归档、丢弃、报错、非法字符替换为指定字符串非法字符替换为指定字符串:将原始表名中的特殊字符替换为后方输入框中的指定字符串,例如
a.b替换为a_b - 表名模板变量空值 检查子表表名模板中的变量是否为空,可选处理策略:丢弃、留空、变量替换为指定字符串
留空:变量位置不做任何特殊处理,例如
a_{x}转换为a_变量替换为指定字符串:变量位置使用后方输入框中的指定字符串,例如a_{x}转换为a_b - 列名不存在 写入报错列名不存在,可选处理策略:归档、丢弃、报错、自动增加缺失列
自动增加缺失列:根据数据信息,自动修改表结构增加列,修改成功后重试
- 列名长度溢出 检查列名的长度是否超出限制(最大 64 字符),可选处理策略:归档、丢弃、报错
- 列自动扩容 开关选项,打开时,列数据长度超长时将自动修改表结构并重试
- 列长度溢出 写入报错列长度溢出,可选处理策略:归档、丢弃、报错、截断、截断且归档
截断:截取数据中符合长度限制的前 n 个字符
截断且归档:截取数据中符合长度限制的前 n 个字符,并且将此行记录写入归档文件 - 数据异常 其他数据异常(未在上方列出的其他异常)的处理策略,可选处理策略:归档、丢弃、报错
- 连接超时 配置目标库连接超时时间,单位“秒”取值范围 1~600
- 临时存储文件位置 配置缓存文件的位置,实际生效位置
$DATA_DIR/tasks/:id/{location} - 归档数据保留天数 非负整数,0 表示无限制
- 归档数据可用空间 0~65535,其中 0 表示无限制
- 归档数据文件位置 配置归档文件的位置,实际生效位置
$DATA_DIR/tasks/:id/{location} - 归档数据失败处理策略 当写入归档文件报错时的处理策略,可选处理策略:删除旧文件、丢弃、报错并停止任务
删除旧文件:删除旧文件,如果删除旧文件后仍然无法写入,则报错并停止任务 丢弃:丢弃即将归档的数据 报错并停止任务:报错并停止当前任务
10. 创建完成
点击 提交 按钮,完成创建 MySQL 到 TDengine TSDB 的数据同步任务,回到数据源列表页面可查看任务执行情况。










