CSV
本节讲述如何通过 Explorer 界面创建数据迁移任务,从 CSV 迁移数据到当前 TDengine TSDB 集群。
功能概述
导入一个或多个 CSV 文件数据到 TDengine TSDB。
创建任务
1. 新增数据源
在数据写入任务列表页面中,点击 +新建任务 按钮,进入新建任务页面。

2. 配置基本信息
在 名称 中输入任务名称,如:“test_csv”。
在 类型 下拉列表中选择 CSV。
在 目标数据库 下拉列表中选择一个目标数据库,也可以先点击右侧的 +创建数据库 按钮。

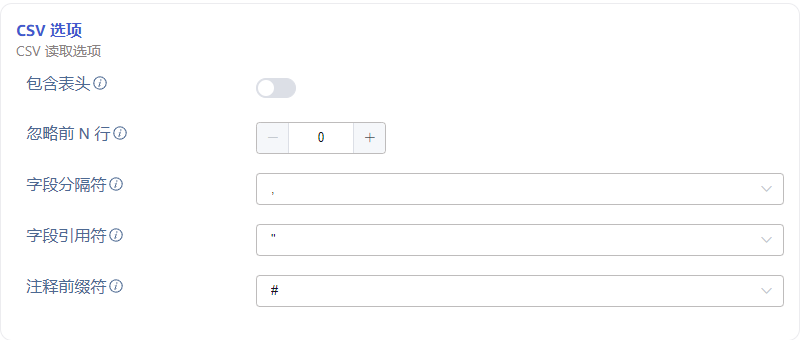
3. 配置 CSV 选项
在 包含表头 区域点击开启或关闭,如果包含表头,则 CSV 文件内容第一行将被视为列信息。
在 忽略前 N 行 区域填写数字 N,表示忽略 CSV 文件的前 N 行。
在 字段分隔符 区域选择 CSV 字段分隔符,用于分隔行内容为多个字段,默认是 ,。
在 字段引用符 区域选择 CSV 字段引用符,当 CSV 字段中包含分隔符或换行符时,用于包围字段内容,以确保整个字段被正确识别,默认是 "。
在 注释前缀符 区域选择 CSV 行注释前缀符,当 CSV 文件中某行以此处指定的字符开头,则忽略该行,默认是 #。
4. 配置解析 CSV 文件
4.1 配置数据源
包含“上传 CSV 文件”与“监听文件目录”两种方式,“上传 CSV 文件”是指将本地文件通过浏览器上传到 taosx 所在服务器作为数据源,“监听文件目录”是指配置一个 taosx 所在服务器的绝对路径作为数据源,以下将分别进行介绍:
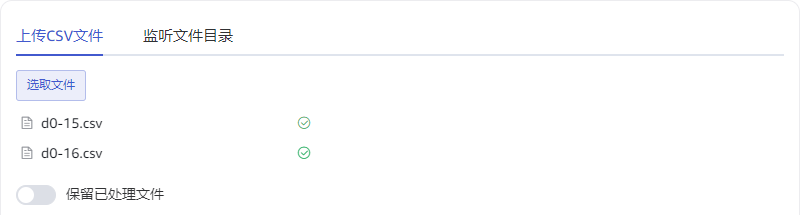
4.1.1 上传 CSV 文件
在“上传 CSV 文件”标签页中:
点击 选取文件 按钮,选取一个或多个本地文件,上传到服务器作为数据源。
在 保留已处理文件 区域点击开启或关闭,如果开启,则文件被处理完成后仍会保留在服务器中,如果关闭,则将被删除。
4.1.2 监听文件目录
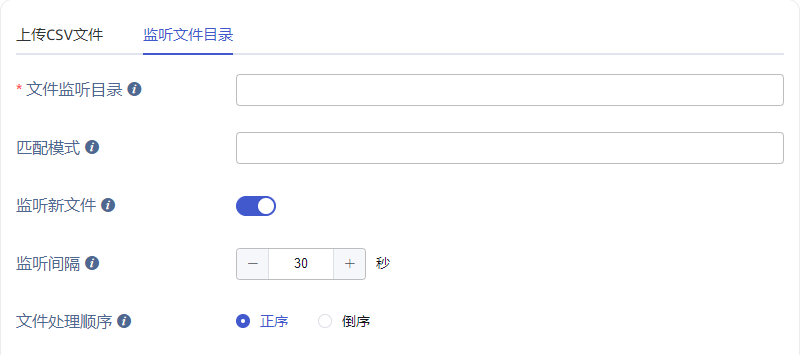
在“监听文件目录”标签页中:
在 文件监听目录 中输入一个 taosx 所在服务器的绝对路径,路径中包含的文件及子目录文件将作为数据源。
在 匹配模式 中输入一个正则表达式,用于筛选过滤目录中的文件。
在 监听新文件 区域点击开启或关闭,如果开启,则任务永不停止,且持续处理目录中新增的文件,如果关闭,则不处理新增文件,且初始文件处理结束后任务变为完成状态。
在 监听间隔 中输入一个数字,用于配置监听新文件的时间间隔。
在 文件处理顺序 区域选择“正序”或“倒序”,用于指定文件列表的处理先后顺序,“正序”将按照文件名的字典序正序处理,“倒序”将按照文件名的字典序倒序处理,与此同时,程序总是保持先处理文件后处理同级子目录的顺序。
4.2 解析
上传文件或配置监听目录后,点击解析按钮,页面将获取文件中的示例数据,同时得到识别的列与示例数据解析结果:
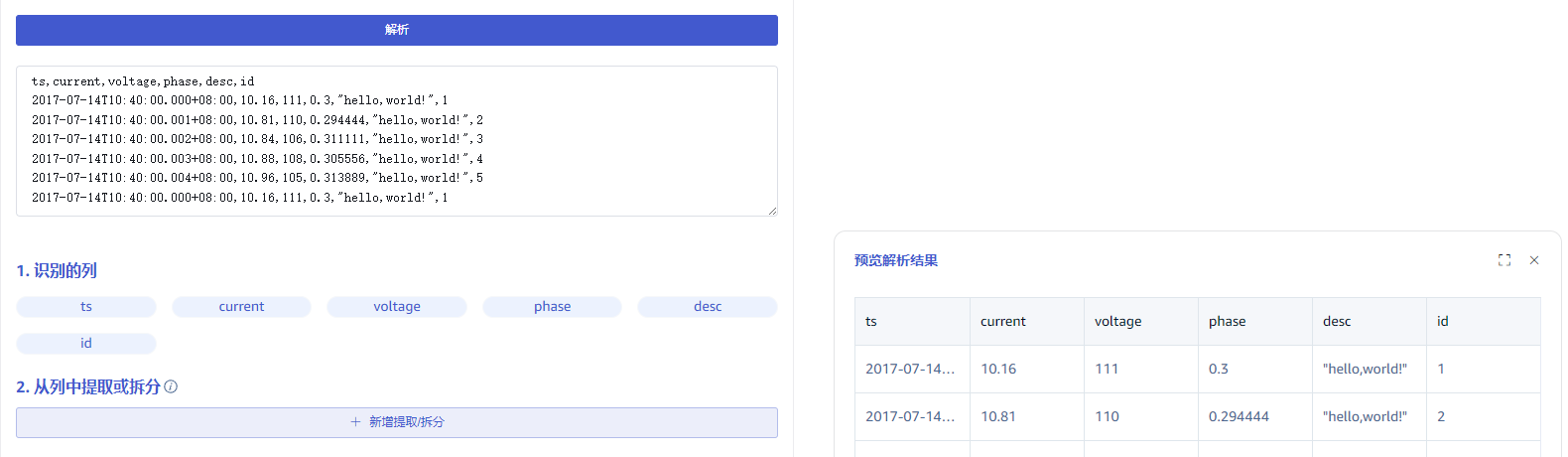
4.2 从列中提取或拆分
在 从列中提取或拆分 中填写从消息体中提取或拆分规则,例如:将 desc 字段拆分为 desc_0 与 desc_1 两个字段,可以选择 split 规则,separator 填写 ,,number 填写 2 即可。
点击 删除 可以删除当前提取规则。
点击 预览 可以预览提取或拆分结果。
点击 新增提取/拆分 可以添加更多提取规则。

4.3 过滤
在 过滤 中填写过滤条件,例如:填写 id != "1",则只有 id 不为 1 的数据才会被处理。
点击 删除 可以删除当前过滤规则。
点击 预览 可以预览过滤结果。
点击 新增过滤 可以添加更多过滤规则。

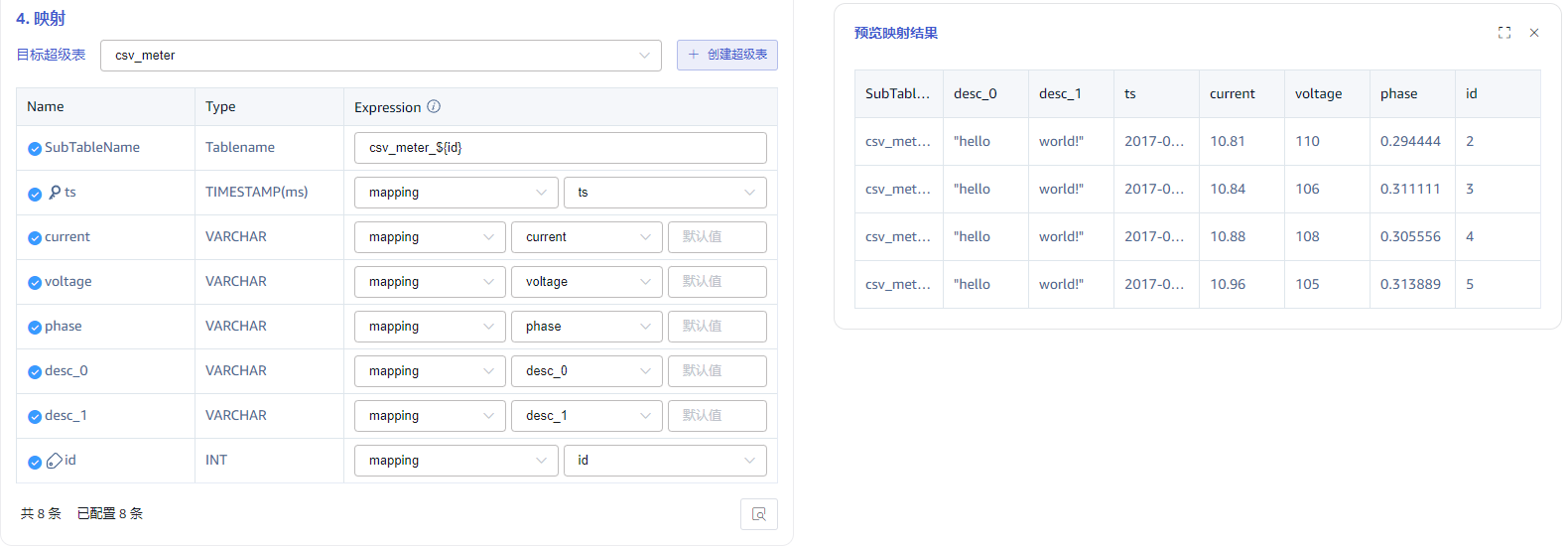
4.4 映射
在 目标超级表 的下拉列表中选择一个目标超级表,也可以先点击右侧的 创建超级表 按钮。由于普通表并非典型应用场景,暂时不支持导入到普通表。
在映射规则中,填写目标超级表中的子表名称,例如:csv_meter_${id},同时配置映射到超级表的列。
点击 预览 可以预览映射的结果。
5. 配置高级选项
高级选项 区域是默认折叠的,点击右侧 > 可以展开,如下图所示:
最大读取并发数 数据源连接数或读取线程数限制,当默认参数不满足需要或需要调整资源使用量时修改此参数。
批次大小 单次发送的最大消息数或行数。默认是 10000。
6. 异常处理策略
异常处理策略区域是对数据异常时的处理策略进行配置,默认折叠的,点击右侧 > 可以展开,如下图所示:
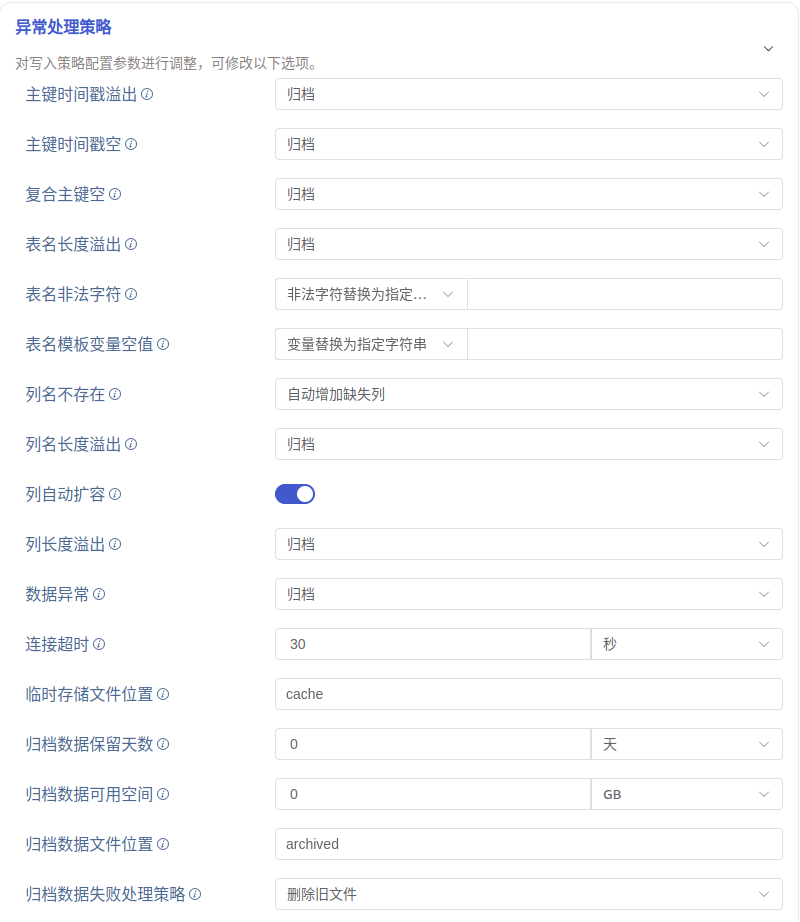
各异常项说明及相应可选处理策略如下:
通用处理策略说明:
归档:将异常数据写入归档文件(默认路径为${data_dir}/tasks/_id/.datetime),不写入目标库
丢弃:将异常数据忽略,不写入目标库
报错:任务报错
- 目标库连接超时 目标库连接失败,可选处理策略:归档、丢弃、报错、缓存
缓存:当目标库状态异常(连接错误或资源不足等情况)时写入缓存文件(默认路径为
${data_dir}/tasks/_id/.datetime),目标库恢复正常后重新入库 - 目标库不存在 写入报错目标库不存在,可选处理策略:归档、丢弃、报错
- 表不存在 写入报错表不存在,可选处理策略:归档、丢弃、报错、自动建表
自动建表:自动建表,建表成功后重试
- 主键时间戳溢出 检查数据中第一列时间戳是否在正确的时间范围内(now - keep1, now + 100y),可选处理策略:归档、丢弃、报错
- 主键时间戳空 检查数据中第一列时间戳是否为空,可选处理策略:归档、丢弃、报错、使用当前时间
使用当前时间:使用当前时间填充到空的时间戳字段中
- 复合主键空 写入报错复合主键空,可选处理策略:归档、丢弃、报错
- 表名长度溢出 检查子表表名的长度是否超出限制(最大 192 字符),可选处理策略:归档、丢弃、报错、截断、截断且归档
截断:截取原始表名的前 192 个字符作为新的表名
截断且归档:截取原始表名的前 192 个字符作为新的表名,并且将此行记录写入归档文件 - 表名非法字符 检查子表表名中是否包含特殊字符(符号
.等),可选处理策略:归档、丢弃、报错、非法字符替换为指定字符串非法字符替换为指定字符串:将原始表名中的特殊字符替换为后方输入框中的指定字符串,例如
a.b替换为a_b - 表名模板变量空值 检查子表表名模板中的变量是否为空,可选处理策略:丢弃、留空、变量替换为指定字符串
留空:变量位置不做任何特殊处理,例如
a_{x}转换为a_变量替换为指定字符串:变量位置使用后方输入框中的指定字符串,例如a_{x}转换为a_b - 列名不存在 写入报错列名不存在,可选处理策略:归档、丢弃、报错、自动增加缺失列
自动增加缺失列:根据数据信息,自动修改表结构增加列,修改成功后重试
- 列名长度溢出 检查列名的长度是否超出限制(最大 64 字符),可选处理策略:归档、丢弃、报错
- 列自动扩容 开关选项,打开时,列数据长度超长时将自动修改表结构并重试
- 列长度溢出 写入报错列长度溢出,可选处理策略:归档、丢弃、报错、截断、截断且归档
截断:截取数据中符合长度限制的前 n 个字符
截断且归档:截取数据中符合长度限制的前 n 个字符,并且将此行记录写入归档文件 - 数据异常 其他数据异常(未在上方列出的其他异常)的处理策略,可选处理策略:归档、丢弃、报错
- 连接超时 配置目标库连接超时时间,单位“秒”取值范围 1~600
- 临时存储文件位置 配置缓存文件的位置,实际生效位置
$DATA_DIR/tasks/:id/{location} - 归档数据保留天数 非负整数,0 表示无限制
- 归档数据可用空间 0~65535,其中 0 表示无限制
- 归档数据文件位置 配置归档文件的位置,实际生效位置
$DATA_DIR/tasks/:id/{location} - 归档数据失败处理策略 当写入归档文件报错时的处理策略,可选处理策略:删除旧文件、丢弃、报错并停止任务
删除旧文件:删除旧文件,如果删除旧文件后仍然无法写入,则报错并停止任务 丢弃:丢弃即将归档的数据 报错并停止任务:报错并停止当前任务
7. 创建完成
点击 提交 按钮,完成创建 CSV 到 TDengine TSDB 的数据同步任务,回到数据写入任务列表页面,可查看任务执行情况,也可以进行任务的“启动/停止”操作与“查看/编辑/删除/复制”操作。

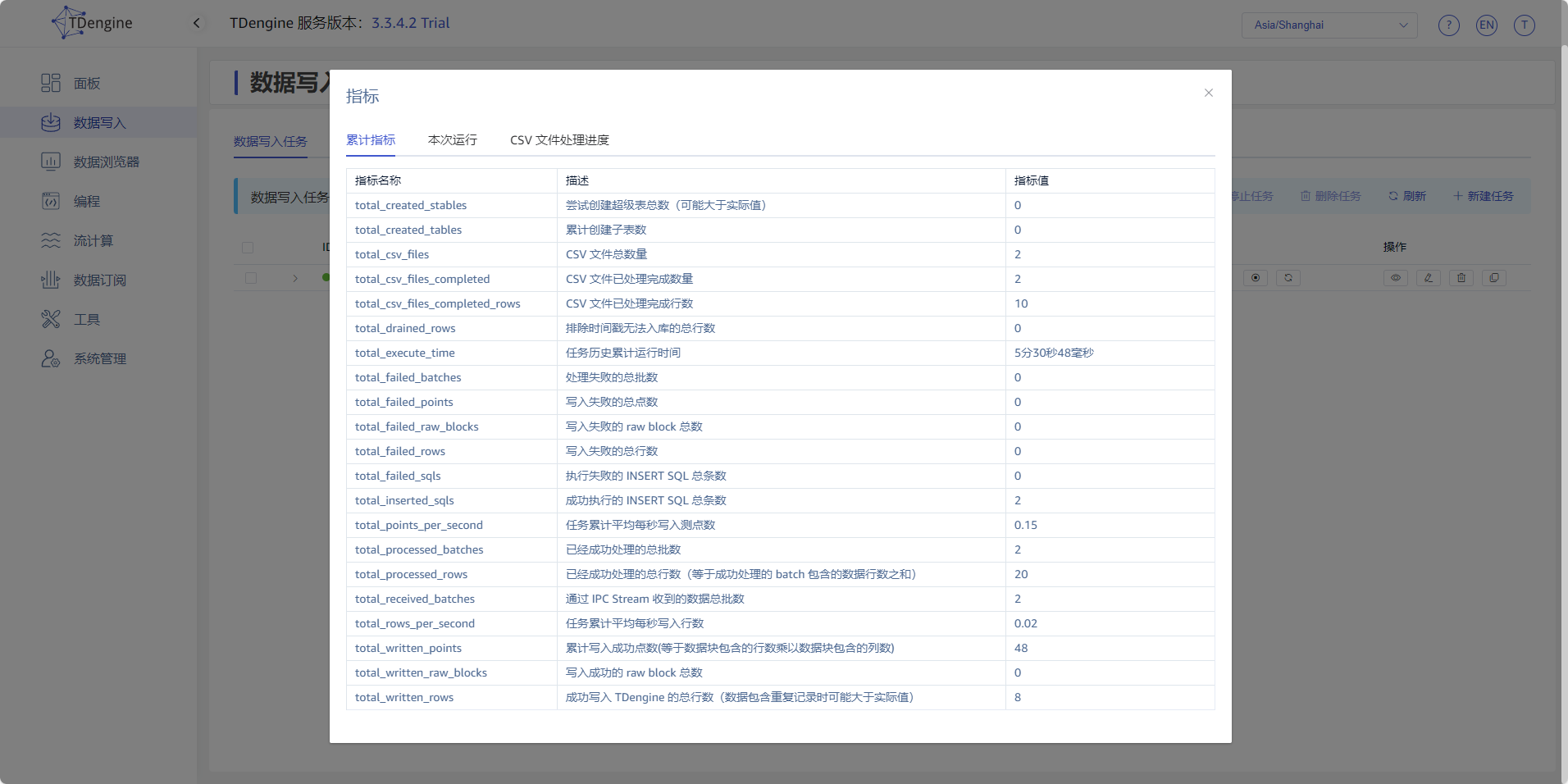
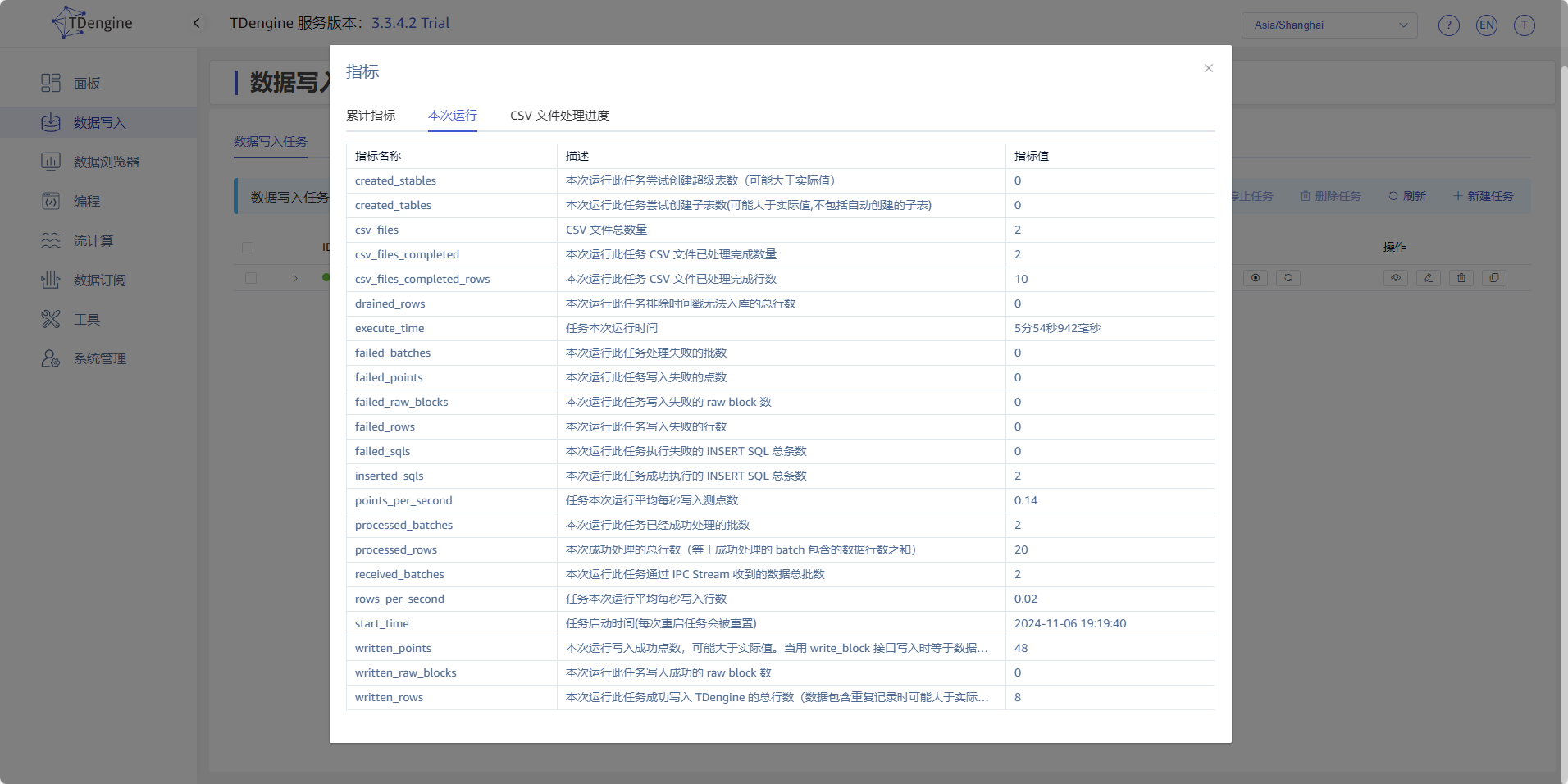
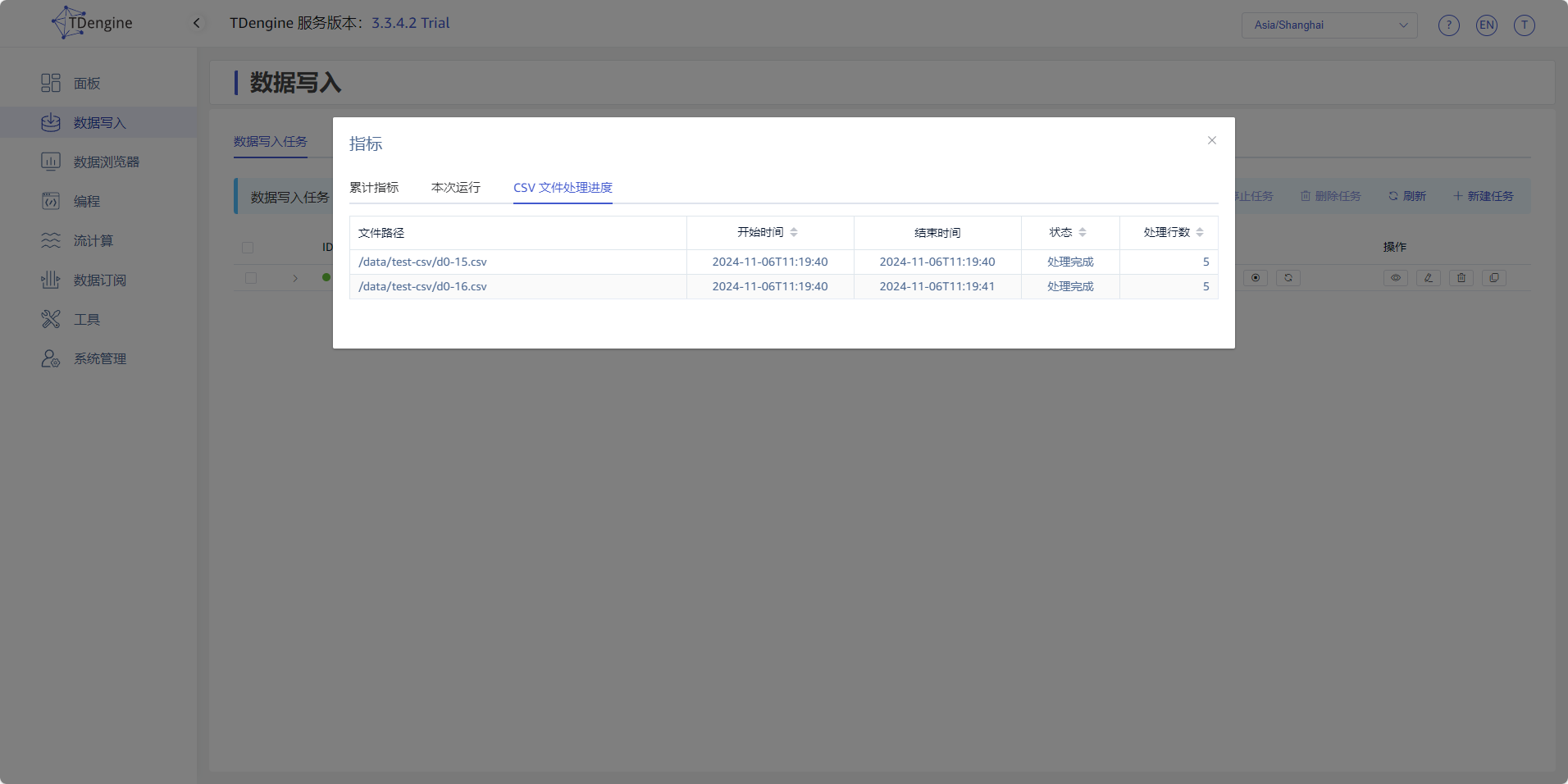
8. 查看运行指标
点击 查看 按钮,查看任务的运行指标,同时也可以查看任务中所有文件的处理情况。