模型评估工具
TDgpt 在企业版中提供预测分析模型和异常检测模型有效性评估工具 analytics_compare,该工具能够使用 TDengine TSDB 中的时序数据作为
回测依据,评估不同预测模型或训练模型的有效性。
该工具在开源版本中不可用
使用评估工具,需要在其相关的配置文件 taosanode.ini 中设置正确的参数,包括选取评估的数据范围、结果输出时间、参与评估的模型、模型的参数、是否生成预测结果图等配置。
在具备完备的 Python 库的运行环境中,通过 shell 调用 TDgpt 安装路径下的 misc 中 analytics_compare 的命令即可。
可按照如下方式体验模型有效性评估工具:
在配置文件 analytics.ini 配置文件中设置 taosd 服务的连接信息,包括 主机地址、配置文件路径、用户名、登录密码等信息。
[taosd]
# taosd 服务主机名
host = 127.0.0.1
# 登录用户名
user = root
# 登录密码
password = taosdata
# 配置文件路径
conf = /etc/taos/taos.cfg
[input_data]
# 用于预测评估的数据库名称
db_name = test
# 读取数据的表名称
table_name = passengers
# 读取列名称
column_name = val, _c0
评估预测分析模型
- 准备数据
在 TDgpt 安装目录下的 resource 文件夹中准备了样例数据 sample-fc.sql, 执行以下命令即可将示例数据写入数据库,用于执行评估
taos -f sample-fc.sql
- 设置参数
[forecast]
# 评估用数据每个周期包含的数据点数量
period = 12
# 预测生成结果的数据点数量
rows = 10
# 评估用数据起始时间
start_time = 1949-01-01T00:00:00
# 评估用数据结束时间
end_time = 1960-12-01T00:00:00
# 返回结果的时间戳起始值
res_start_time = 1730000000000
# 是否绘制预测结果
gen_figure = true
[forecast.algos]
# 评估用的模型及参数
holtwinters={"trend":"add", "seasonal":"add"}
arima={"time_step": 3600000, "start_p": 0, "max_p": 5, "start_q": 0, "max_q": 5}
- 调用评估工具
python3 ./analytics_compare.py forecast
需确保激活虚拟环境并调用该虚拟环境的 Python,否则启动的时候 Python 会提示找不到所需要的依赖库。
- 检查结果
在程序目录下生成 fc_result.xlsx 文件,此文件即为模型评估的结果文件。预测有效性的评估使用 MSE 指标作为依据,后续还将增加 MAPE 和 MAE 指标。
该文件中第一个卡片是模型运行结果(如下表所示),分别是模型名称、执行调用参数、均方误差、执行时间 4 个指标。
| algorithm | params | MSE | elapsed_time(ms.) |
|---|---|---|---|
| holtwinters | {"trend":"add", "seasonal":"add"} | 351.622 | 125.1721 |
| arima | {"time_step":3600000, "start_p":0, "max_p":10, "start_q":0, "max_q":10} | 433.709 | 45577.9187 |
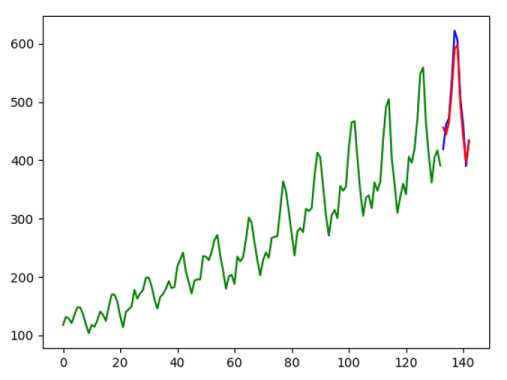
如果配置文件 analytics.ini 中设置 gen_figure 为 true,分析结果文件中的后续卡片中在针对每个模型绘制分析预测结果图(如下图)。
评估异常检测模型
针对异常检测模型提供查全率(recall)和查准率(precision)两个指标衡量模型有效性。
通过在配置文件中analysis.ini设置以下的选项可以调用需要使用的异常检测模型,异常检测模型测试用数据的时间范围、是否生成标注结果的图片、调用的异常检测模型以及相应的参数。
- 准备数据
在 TDgpt 安装目录下的 resource 文件夹中准备了样例数据 sample-ad.sql, 执行以下命令即可将示例数据写入数据库
taos -f sample-ad.sql
- 设置参数
[ad]
# 数据集起始时间戳
start_time = 2021-01-01T01:01:01
# 数据集结束时间戳
end_time = 2021-01-01T01:01:11
# 是否绘制检测结果
gen_figure = true
# 标注异常检测结果
anno_res = [9]
# 用于比较的模型及相关参数设置
[ad.algos]
ksigma={"k": 2}
iqr={}
grubbs={}
lof={"algorithm":"auto", "n_neighbor": 3}
-
标注异常检测结果 调用异常检测模型比较之前,需要人工标注异常监测数据集结果,即在 [anno_res] 选项下标注异常点在测试数组中的位置。 例如:在 sample-ad 测试数据集中第 9 个点是异常点。需要在 [anno_res] 下异常标注 [9]。如果第 0 个点和第 9 个点是异常点,则 设置为 [0, 9]
-
调用评估工具
python3 ./analytics_compare.py anomaly-detection
- 检查结果
对比程序执行完成以后,会自动生成名称为 ad_result.xlsx 的文件,第一个卡片是模型运行结果(如下表所示),分别是模型名称、执行调用参数、查全率、查准率、执行时间 5 个指标。
| algorithm | params | precision(%) | recall(%) | elapsed_time(ms.) |
|---|---|---|---|---|
| ksigma | {"k":2} | 100 | 100 | 0.453 |
| iqr | {} | 100 | 100 | 2.727 |
| grubbs | {} | 100 | 100 | 2.811 |
| lof | {"algorithm":"auto", "n_neighbor":3} | 0 | 0 | 4.660 |
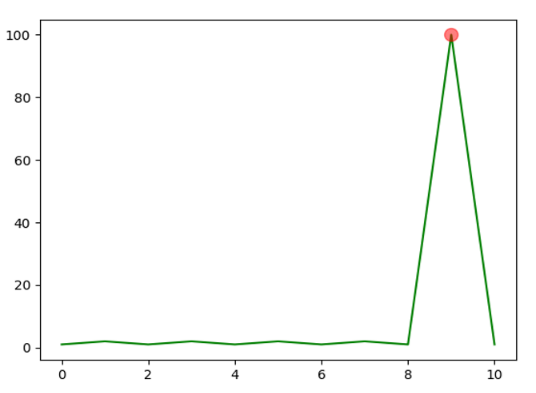
如果设置了 gen_figure 为 true,比较程序会自动将每个参与比较的模型分析结果采用图片方式呈现出来(如下图所示为 ksigma 的异常检测结果标注)。