数据分析预处理
分析流程
时序数据分析之前需要有预处理的过程,为减轻分析算法的负担,TDgpt 在将时序数据发给具体分析算法进行分析时,已经对数据做了预处理,整体的流程如下图所示。
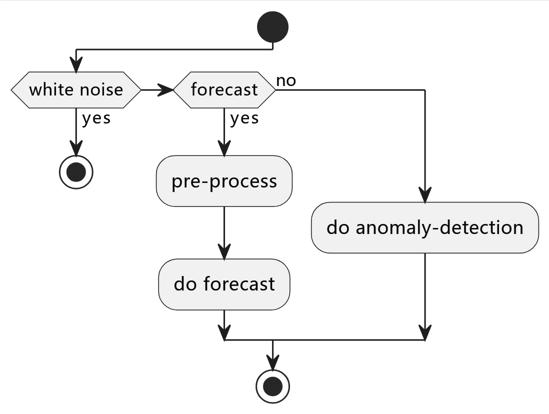
TDgpt 首先对输入数据进行白噪声检查(White Noise Data check), 检查通过以后针对预测分析,还要进行输入(历史)数据的重采样和时间戳对齐处理(异常检测跳过数据重采样和时间戳对齐步骤)。 预处理完成以后,再进行预测或异常检测操作。预处理过程不属于预测或异常检测处理逻辑的一部分。
白噪声检查
白噪声时序数据可以简单地认为是随机数构成的时间数据序列(如上图所示的正态分布随机数序列),随机数构成的时间序列没有分析的价值,因此会直接返回。白噪声检查采用经典的 Ljung-Box 统计量检验,计算 Ljung-Box 统计量需遍历整个输入时间序列。如果用户能够明确输入序列一定不是白噪声序列,那么可以在参数列表中增加参数 wncheck=0 强制要求分析平台忽略白噪声检查,从而节省计算资源。
TDgpt 暂不提供独立的时间序列白噪声检测功能。
重采样和时间戳对齐
对于进行预测分析的时间序列数据,在进行预测分析前需要进行必要的预处理。预处理主要解决以下两个问题。
-
真实时间序列数据时间戳未对齐。由于数据生成设备的原因或网关赋值时间戳的时候并不能保证按照严格的时间间隔赋值,时间序列数据并不能保证是严格按照采样频率对齐。例如采样频率为 1Hz 的一个时间序列数据序列,其时间戳序列如下。
['20:12:21.143', '20:12:22.187', '20:12:23.032', '20:12:24.384', '20:12:25.033']
预测返回的时间序列时间戳会严格对齐,例如返回后续的两个预测结果的时间戳,其时间一定如下:['20:12:26.000', '20:12:27.000']。因此上述的输入时间戳序列要进行时间戳对齐,变换成为如下时间戳序列。
['20:12:21.000', '20:12:22.000', '20:12:23.000', '20:12:24.000', '20:12:25.000']
-
数据时间重采样。用户输入时间序列的采样频率超过了输出结果的频率,例如输入时间序列的采样时间间隔是 5 sec,但是要求输出预测结果的采样时间间隔是 10sec。
['20:12:20.000', '20:12:25.000', '20:12:30.000', '20:12:35.000', '20:12:40.000']
重采样为采样间隔为 10sec 的时间戳序列。
['20:12:20.000', '20:12:30.000', '20:12:40.000']
然后将其作为预测分析的输入,['20:12:25.000', '20:12:35.000'] 数据被丢弃。
需要注意的是,预处理过程不支持缺失数据补齐操作,如果输入时间序列数据 ['20:12:10.113', '20:12:21.393', '20:12:29.143', '20:12:51.330'],并且要求的采样时间间隔为 10sec,重整对齐后的时间戳序列是 ['20:12:10.000', '20:12:20.000', '20:12:30.000', '20:12:50.000'],那么对该序列进行预测分析将返回错误。










