背景介绍
针对时间序列数据预测分析、异常检测、数据补全和数据分类的应用领域,相关领域的研究人员提出并开发出了众多不同技术特点、适用于不同场景的时序数据分析算法,广泛应用在时间序列数据预测、异常检测等领域。
分析算法通常以高级编程语言(Python 语言或 R 语言)工具包的形式存在,并通过开源的方式广泛分发和使用,这种应用模式极大地便利了软件开发人员在应用系统中调用复杂的分析算法,极大地降低了使用高级算法的门槛。
另一方面,数据库系统研发人员尝试将数据分析算法模型整合到数据库系统中,通过建立 Machine Learning 库(例如 Spark MLLib1 等),充分利用成熟分析技术增强数据库或分析计算引擎的高级数据分析能力。
飞速发展的人工智能(AI)技术为时序数据分析应用带来了新机遇,如何快速高效地将 AI 能力应用于时间序列数据分析,也对数据库系统提出了新挑战。为此,涛思数据创新性地提出时序数据分析智能体 TDgpt。借助 TDgpt 用户能够使用 SQL 语句,直接调用适配和整合统计分析算法、机器学习算法模型、深度学习模型,时序数据基础模型以及大语言模型,并将这些分析能力转化为 SQL 语句的调用,通过异常检测窗口和预测函数的方式应用在时序数据上。
技术特点
TDgpt 是与 TDengine TSDB 主进程 taosd 适配的外置式时序数据分析智能体,能够将时序数据分析服务无缝集成在 TDengine TSDB 的查询执行流程。 TDgpt 是一个无状态的平台,其内置了经典的统计分析模型库 Statsmodel、Pycularity 等,内嵌了 PyTorch/Keras 等机器/深度学习框架库,此外还通过请求转发和适配的方式直接调用涛思数据自研的时序数据基础大模型 TDtsfm (TDengine TSDB time series foundation model)。
作为一个分析智能体,TDgpt 后续还将整合第三方时序数据 MaaS 大模型服务,仅修改一个参数(algo)就能够调用最先进的时间序列模型服务。 TDgpt 是一个开放的系统,用户能够根据自己的需要,添加预测分析、异常检测、数据补全、数据分类算法,添加完成后,仅通过修改 SQL 语句中调用的算法参数就能够无缝使用新加入的算法。 无需应用修改一行代码。
系统架构
TDgpt 由若干个无状态的分析节点 Anode 构成,可以按需在系统集群中部署 Anode 节点,也可以根据分析模型算法的特点,将 Anode 部署在合适的硬件环境中,例如带有 GPU 的计算节点。 TDgpt 针对不同的分析算法,提供统一的调用接口和调用方式,根据用户请求的参数,调用高级分析算法包及其他的分析工具,并将分析获得的结果按照约定的方式返回给 TDengine TSDB 的主进程 taosd。 TDgpt 主要包含四个模块:
- 第一部分是内置分析库,包括 statsmodels2, pyculiarity, pmdarima 等,提供可以直接调用的预测分析和异常检测算法模型。
- 第二部分是内置的机器学习库(包括:PyTorch3、keras4、scikit-learn5 等),用于驱动预训练完成的机器(深度)学习模型在 TDgpt 的进程空间内运行。预训练的流程可以使用 Merlion/Kats 等 开源的端到端机器学习框架进行管理,并将完成训练的模型上传到 TDgpt 指定目录即可。
- 第三部分是通用大语言模型的请求适配模块。将时序数据预测请求转换后,基于 Prompt 向 DeepSeek6、LlaMa7 等通用大语言模型 MaaS 请求服务(这部分功能暂未开源)。
- 第四部分是通过 Adapter 直接向本地部署的 Time-MoE8、TDtsfm 等时序数据模型请求服务。时序数据专用模型相对于通用语言大模型,无需 Prompt,更加便捷轻量,本地应用部署对硬件资源要求也较低;除此之外,Adapter 还可以直接请求 TimeGPT9 这种类型的时序数据分析 MaaS 服务,调用云端的时序模型服务提供本地化时序数据分析能力。
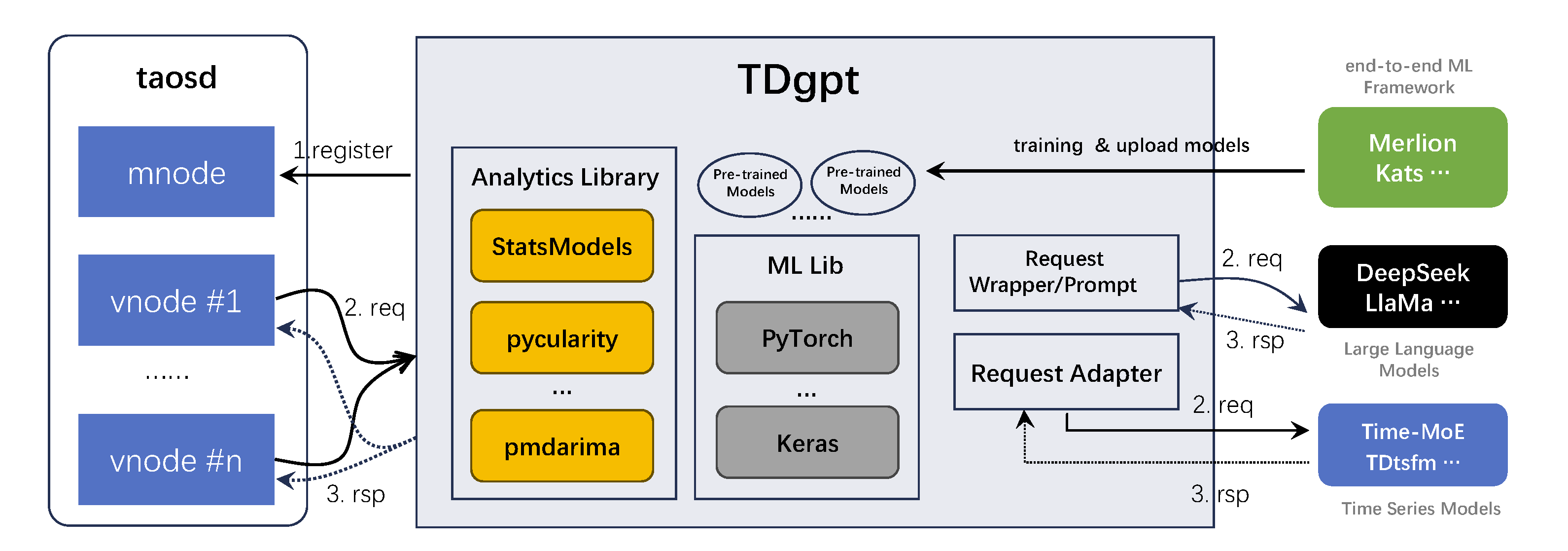
查询过程中,TDengine TSDB 中的 Vnode 会将涉及时序数据高级分析的部分直接转发到 Anode,并等待分析完成后将结果组装完成,嵌入查询执行流程。
时序数据分析服务
TDgpt 的时序数据分析功能包括:
- 时序数据异常检测:TDengine TSDB 中定义了新的时间窗口 异常(状态)窗口 来提供异常检测服务。异常窗口可以视为一种特殊的事件窗口(Event Window),即异常检测算法确定的连续异常时间序列数据所在的时间窗口。与普通事件窗口区别在于,时间窗口的起始时间和结束时间均是分析算法确定,不是用户指定的表达式判定。异常窗口使用方式与其他类型的时间窗口(例如状态窗口、会话窗口等)类似。因此时间窗口内可使用的查询操作均可应用在异常窗口上。
- 时序数据分析预测:TDengine TSDB 中提供了一个新的函数 FORECAST 提供时序数据预测服务,基于输入的(历史)时间序列数据调用指定(或默认)预测算法给出输入时序数据后续时间序列的预测数据。
- 时序数据补全:基于时序基础模型提供的能力,自动检测输入时序数据缺失的数据点,并补齐其中缺失的时间戳以及对应的数值。
- 时序数据分类:研发测试中,2025 年 12 月发布
自定义分析算法
TDgpt 是一个可扩展的时序数据高级分析智能体,用户遵循 算法开发者指南 中的简易步骤就能将自己开发的分析算法添加到系统中。之后应用可以通过 SQL 语句直接调用,让高级分析算法的使用门槛降到几乎为零。对于新引入的算法或模型,应用不用做任何调整。
TDpgt 只支持使用 Python 语言开发的分析算法。Anode 采用 Python 类动态加载模式,在启动的时候扫描特定目录内满足约定条件的所有代码文件,并将其加载到系统中。因此,开发者只需要遵循以下几步就能完成新算法的添加工作。
- 开发完成符合要求的分析算法类。
- 将代码文件放入对应目录,然后重启 Anode。
- 使用 SQL 命令更新算法缓存列表即可。 添加完成的算法在刷新算法列表后,立即使用 SQL 语句进行调用。
模型评估工具
TDgpt 企业版提供针对多种算法模型有效性的综合评估工具。该工具可以针对 TDgpt 可调用所有时序数据分析(预测分析与异常检测)服务,包括内置数据分析算法模型,已部署的预训练机器学习模型、第三方时序数据(大)模型服务,基于 TDengine TSDB 中的时序数据进行预测分析对比和异常检测对比评估,并给出量化指标评估不同分析模型在给定数据集上准确度及性能。
模型管理
对于 PyTorch、Tensorflow、Keras 等机器学习库框架驱动的预训练模型,需要首先将训练完成的数据模型添加到 Anode 的指定目录中,Anode 可以自动调用该目录内的模型,驱动其运行并提供服务。 企业版本的 TDgpt 具备模型的管理能力,能够与开源的端到端时序数据机器学习框架(例如:Merlion10、Kats11 等)无缝集成。
处理能力
通常意义上,时间序列数据分析主要是计算密集型任务。这种计算密集型任务,可以使用更高性能的 CPU 或 GPU 来提升处理性能。 如果是机器/深度学习模型,依赖于 PyTorch 库驱动其运行,可以采用标准的提升分析处理能力的方案来提升 TDgpt 的服务能力,例如将 Anode 部署在内存更大并具有 GPU 的服务器之上,使用可调用 GPU 的 torch 库驱动模型运行,以提升分析响应能力。 不同的模型、算法可以部署在不同的 Anode 上,增加并行的处理能力。
运营维护
开源版本不提供用户权限和资源控制机制。 TDgpt 默认使用 uWSGI 驱动的 flask 服务,可以通过打开 uWSGI 的端口监控服务的运行状态。 3.4.1 版本之后不再使用 uWSGI, 采用 Gunicore 驱动服务,










