预测分析
时序数据预测分析以持续一个时间段的时序数据作为输入,预测接下一个连续时间区间内时间序列数据趋势,并且用户可以指定(预测)输出的时间序列数据点数量。TDengine TSDB 引入新的 SQL 函数 FORECAST 提供预测分析功能。基础(用于预测的历史时间序列)数据是该函数的输入,输出即为预测结果。用户可以通过 FORECAST 函数调用 TDgpt 提供的预测算法提供的服务。预测分析通常只能针对超级表的子表或者不同表中同一个时间序列。
在后续章节中,使用时序数据表 foo 作为示例,介绍预测和异常检测算法的使用方式,foo 表模式定义如下:
| 列名称 | 类型 | 说明 |
|---|---|---|
| ts | timestamp | 主时间戳列 |
| val | integer | 4 字节整数,测量值 |
| past_co_val | integer | 4 字节整数,历史协变量数据 |
| future_co_val | integer | 4 字节整数,未来协变量数据 |
taos> select * from foo limit 8;
ts | val | past_co_val | future_co_val |
======================================================================
2020-01-01 00:00:12.681 | 13 | 1| 1 |
2020-01-01 00:00:13.727 | 14 | 2| 1 |
2020-01-01 00:00:14.378 | 8 | 3| 1 |
2020-01-01 00:00:15.774 | 10 | 4| 1 |
2020-01-01 00:00:16.170 | 16 | 5| 1 |
2020-01-01 00:00:17.558 | 26 | 6| 1 |
2020-01-01 00:00:18.938 | 32 | 7| 1 |
2020-01-01 00:00:19.308 | 27 | 8| 1 |
语法
FORECAST(column_expr, option_expr)
option_expr: {"
algo=expr1
[,wncheck=1|0]
[,conf=conf_val]
[,every=every_val]
[,rows=rows_val]
[,start=start_ts_val]
[,timeout=timeout_val]
[,expr2]
"}
column_expr:预测的时序数据列,只支持数值类型列输入。options:预测函数的参数。字符串类型,其中使用 K=V 方式调用算法及相关参数。采用逗号分隔的 K=V 字符串表示,其中的字符串不需要使用单引号、双引号、或转义号等符号,不能使用中文及其他宽字符。预测支持conf、every、rows、start、rows几个控制参数,其含义如下。
参数说明
| 参数 | 含义 | 默认值 |
|---|---|---|
| algo | 预测分析使用的算法 | holtwinters |
| wncheck | 白噪声(white noise data)检查 | 默认值为 1,0 表示不进行检查 |
| conf | 预测数据的置信区间范围,取值范围 [0, 100]; 3.3.6.4 版本开始该参数取值范围调整为 (0, 1], 默认值为 0.95 | 0.95 |
| every | 预测数据的采样间隔 | 输入数据的采样间隔,单位同查询的时序数据 |
| start | 预测结果的开始时间戳 | 输入数据最后一个时间戳加上一个采样间隔时间区间 |
| rows | 预测结果的记录数 | 10 |
| timeout | 预测分析等待的最长时间,超时以后自动返回错误;3.3.6.5 版本支持 | 60(秒),默认等待 60(秒),最大值为 1200(秒) |
- 预测查询结果新增三个伪列,具体如下。
_FROWTS:预测结果的时间戳_FLOW:置信区间下界_FHIGH:置信区间上界,对于没有置信区间的预测算法,其置信区间同预测结果
- 更改参数
START:返回预测结果的起始时间,改变起始时间不会影响返回的预测数值,只影响起始时间。 EVERY:可以与输入数据的采样频率不同。采样频率只能低于或等于输入数据采样频率,不能高于输入数据的采样频率。- 对于某些不需要计算置信区间的算法,即使指定了置信区间,返回的结果中其上下界退化成为一个点。
- rows 的最大输出值是 1024,即只能预测 1024 个值。超过输出范围的参数会被自动设置为 1024。
- 预测分析需要至少 10 行数据作为预测依据,最多允许 40000 行数据作为预测依据,部分分析模型接受的输入数据行数更少。
示例
--- 使用 arima 算法进行预测,预测结果是 10 条记录(默认值),数据进行白噪声检查,默认置信区间 95%.
SELECT _flow, _fhigh, _frowts, FORECAST(val, "algo=arima")
FROM foo;
--- 使用 arima 算法进行预测,输入数据的是周期数据,每 10 个采样点是一个周期,返回置信区间是95%的上下边界,同时忽略白噪声检查
SELECT _flow, _fhigh, _frowts, FORECAST(val, "algo=arima,conf=0.95,period=10,wncheck=0")
FROM foo;
taos> select _flow, _fhigh, _frowts, forecast(val) from foo;
_flow | _fhigh | _frowts | forecast(val) |
========================================================================================
10.5286684 | 41.8038254 | 2020-01-01 00:01:35.000 | 26 |
-21.9861946 | 83.3938904 | 2020-01-01 00:01:36.000 | 30 |
-78.5686035 | 144.6729126 | 2020-01-01 00:01:37.000 | 33 |
-154.9797363 | 230.3057709 | 2020-01-01 00:01:38.000 | 37 |
-253.9852905 | 337.6083984 | 2020-01-01 00:01:39.000 | 41 |
-375.7857971 | 466.4594727 | 2020-01-01 00:01:40.000 | 45 |
-514.8043823 | 622.4426270 | 2020-01-01 00:01:41.000 | 53 |
-680.6343994 | 796.2861328 | 2020-01-01 00:01:42.000 | 57 |
-868.4956665 | 992.8603516 | 2020-01-01 00:01:43.000 | 62 |
-1076.1566162 | 1214.4498291 | 2020-01-01 00:01:44.000 | 69 |
单变量与协变量分析预测
TDgpt 支持单变量分析预测 (single-variable forecasting) 。3.3.6.4 版本开始支持历史协变量分析预测 (co-variate forecasting) , 暂不支持静态协变量。
使用协变量分析预测时,需要部署 moirai 时序数据基础模型。此时,参数 algo 只能是 moiria。
在后续的版本中,我们将提供其他时序基础模型(如 timesfm)的协变量预测分析能力。
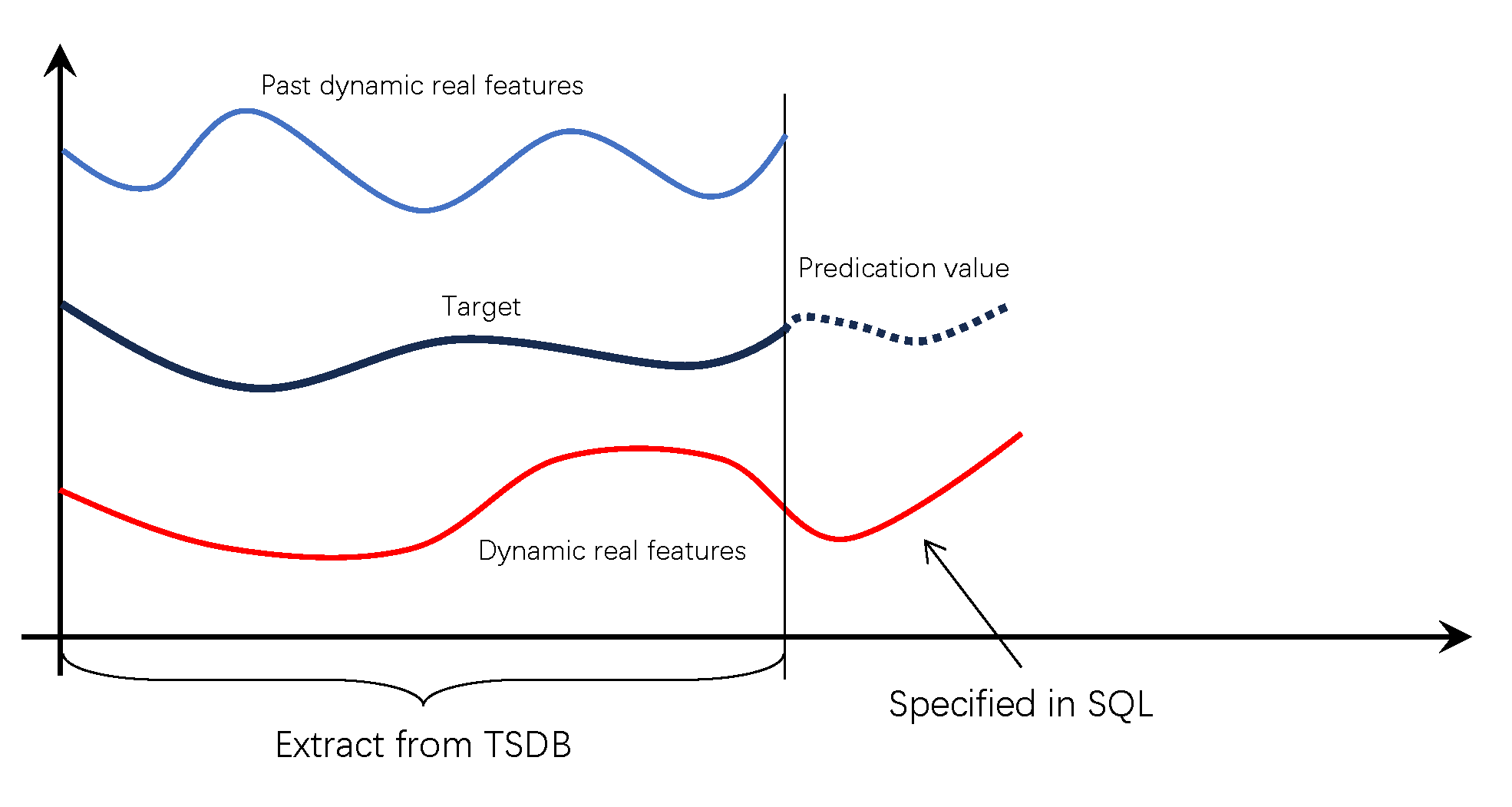
上图中包含两个协变量,一个目标变量(又称为主变量)。其中 Target 是预测分析的目标,Predication value 是预测结果。 Past dynamic real features 是历史协变量,Dynamic real feature 是未来协变量。历史协变量和未来协变量数据与目标变量相同时间区间上的数据是从时序数据库中获取的,未来协变量中与目标时间段对应的数据需要在 SQL 语句中输入。具体使用方式见下面的详细介绍。
历史协变量预测
使用历史协变量预测非常简单,使用如下语句即可调用协变量预测分析服务 (以下语句只能在 3.3.6.4 及以后的版本运行)。
当 forecast 函数输入单列时,为默认的单变量分析预测模式。输入多列时,第一列为主变量,之后的输入数据列是协变量。
所有输入列均只能是数值类型。每次预测查询允许输入的历史协变量数据(列)限制为 10 列,如下 SQL 语句展示了使用协变量的预测分析功能。
---- 第一列(val)为主变量,之后的列(past_co_val)为历史协变量,调用 moirai 基础时序模型
select _frowts, forecast(val, past_co_val, 'algo=moirai') from foo;
未来协变量预测
未来协变量预测的时候,需要设置未来的输入值以及该输入值对应的协变量列。
协变量列的输入需要在 SQL 语句中补充,采用中括号内数组方式,不同的数值之间采用空格分隔。数量应该等于预测分析的数量,如果不等会报错。
未来协变量采用 dynamic_real_ 做为名称的前缀。有多个未来协变量时,可以分别命名为 dynamic_real_1 、dynamic_real_2、dynamic_real_3...,以此类推。
对于每个未来协变量数据,需要设置其关联的未来协变量列。dynamic_real_1 关联的列通过参数 dynamic_real_1_col 设置,dynamic_real_2 关联的列通过参数 dynamic_real_2_col 设置。
如下所示,预测分析针对 val 列进行,同时提供一个历史协变量列 past_co_val,一个未来协变量列 future_co_val,未来协变量列数值通过 dynamic_real_1 设置,数组中有 4 个未来值,通过 dynamic_real_1_col=future_co_val 设置关联的未来协变列是 future_co_val。
select _frowts, forecast(val, past_co_val, future_co_val, "algo=moirai,rows=4, dynamic_real_1=[1 1 1 1], dynamic_real_1_col=future_co_val") from foo;
内置预测算法
- ARIMA
- HoltWinters
- Time Series Foundation Model
- CES (Complex Exponential Smoothing)
- Theta
- Prophet
- XGBoost
- LightGBM
- Multiple Seasonal-Trend decomposition using LOESS (MSTL)
- ETS (Error, Trend, Seasonal)
- Long Short-Term Memory (LSTM)
- Multilayer Perceptron (MLP)
- DeepAR
- N-BEATS
- N-HiTS
- PatchTST (Patch Time Series Transformer)
- Temporal Fusion Transformer
- TimesNet










